As the year changed to 2018, I decided to abandon WordPress, which I had been using for over 12 years as my content management system of choice. I had many reasons to do so, but the biggest motivators were the opportunity to try something new and to abandon the bloat and clutter of WordPress for a more simple, more elegant order of things. Spurred on by another adopter, Mark Edmondson, I decided to give Hugo a go (pun intended).
{kind=link}
The migration wasn’t easy, as I had to convert WordPress’ relational database into a static list of markdown files. Along the way, I had to configure two themes (regular and AMP), optimize all my images, JavaScript, and stylesheets, and go through every single one of my 200+ articles, looking for stylistic issues and broken links (oh boy, were there many of those!).
Hugo is written in the Go language, and it’s fairly easy to use if you’re familiar with markdown and the command line of your operating system. The trick about a static site is that all the content is stored in static files in your file server. There is no relational database to fall back on, which means that a static site can be both blazing fast and a chore to maintain.
One of the biggest headaches for me was how to set up site search. Without a database or a web server generating dynamic HTML documents, finding a suitable way to index the content in the browser and respond quickly and efficiently to search queries seemed like an insurmountable task.
I tried a number of things at first, including:
Algolia, which I had to give up beacuse I had too much content for their free tier.
lunr.js running on a NodeJS virtual machine in Google’s cloud, which I had to give up because I got a bill of 400$ for instance upkeep for the month of December alone.
Custom-built solution that digested JSON generated by Hugo and parsed it for searching with jQuery directly in the browser, which I had to give up since downloading an indexed JSON file of around 5 megabytes on every page is not conducive to a good user experience.
After the failed experiment with lunr.js, I still wanted to give Google’s App Engine another chance. I’ve been in love with App Engine ever since publishing the first version of my GTM Tools on it. Well, as it turns out, App Engine has a really useful and flexible Search API for Python, which seems to be tailormade to work with the JSON generated by Hugo in a static site!
{kind=link}
The Simmer Newsletter
Follow this link to subscribe to the Simmer Newsletter! Stay up-to-date with the latest content from Simo Ahava and the Simmer online course platform.
The setup
My setup looks like this:
The Hugo config file is configured to output an
index.jsoninto the public directory, with all the content of my site ready for indexing.A script which deploys this JSON file into the App Engine project.
An App Engine project which uses the Python Search API client to build an index of this JSON.
The App Engine project also provides an HTTP endpoint to which my site makes all the search queries. Each request is processed as a search query, and the result is returned in the HTTP response.
Finally, I have a bunch of JavaScript running the search form and the search results page on my site, sending the request to the App Engine endpoint as well as formatting the search results page with the response.
The beauty of using the Search API is that I’m well below the quota limits for the free version, and thus I don’t have to pay a dime to make it all work!
{kind=link}
1. The config file modification
The change to Hugo’s config file is easy to make, because Hugo has built in support for generating the JSON in a format that most search libraries digest. In the configuration file, you need to find the output configuration, and add "JSON" as one of the outputs for the home content type. So it looks something like this:
[output]
home = [ "HTML", "RSS", "JSON" ]This configuration change generates an index.json file into the root of your public folder whenever the Hugo project is built.
Here’s an example of a what a blog post might look like in this file:
[
{
"uri": "https://www.simoahava.com/upcoming-talks/",
"title": "Upcoming Talks",
"tags": [],
"description": "My upcoming conference talks and events",
"content": "17 March 2018: MeasureCamp London 20 March 2018: SMX München 19 April 2018: Advanced GTM Workshop (Hamburg) 24 May 2018: NXT Nordic (Oslo) 20 September 2018: Advanced GTM Workshop (Hamburg) 14-16 November 2018: SMXL Milan I enjoy presenting at conferences and meetups, and I have a track record of hundreds of talks since 2013, comprising keynotes, conference presentations, workshops, seminars, and public trainings. Audience sizes have varied between 3 and 2,000.\nMy favorite topics revolve around web analytics development and analytics customization, but I\u0026rsquo;m more than happy to talk about integrating analytics into organizations, knowledge transfer, improving technical skills, digital marketing, and content creation.\nSome of my conference slides can be found at SlideShare.\nFor a sample, here\u0026rsquo;s a talk I gave at Reaktor Breakpoint in 2015.\n You can contact me at simo (at) simoahava.com for enquiring about my availability for your event.\n"
}
]2. The deploy script
The deploy script is a piece of Bash code which builds the Hugo site, copies the index.json into my search project folder, and then deploys the entire search project into App Engine. Here’s what it looks like:
cd ~/Documents/Projects/www-simoahava-com/
rm -rf public
hugo
cp public/index.json ../www-simoahava-com-search/
rm -rf public
cd ~/Documents/Projects/www-simoahava-com-search/
gcloud app deploy
curl https://search-www-simoahava-com.appspot.com/updateThe hugo command builds the site and generates the public folder. From the public folder, the index.json is then copied to my search project folder, which is subsequently deployed into App Engine using the command gcloud app deploy. Finally, a curl command to my custom endpoint makes certain that my Python script updates the search index with the latest version of index.json.
3. The Python code running in App Engine
In App Engine, I’ve simply created a new project with a name that’s easy enough to remember as the endpoint. I haven’t added any billing to the account, because I’ve set a challenge for myself to build a free search API for my site.
See this documentation for a quick start guide on how to get started with Python and App Engine. Focus especially on how to setup the App Engine project (you don’t need to enable billing), and how to install and configure the gcloud command line tools for your project.
The Python code looks like this.
#!/usr/bin/python
from urlparse import urlparse
from urlparse import parse_qs
import json
import re
import webapp2
from webapp2_extras import jinja2
from google.appengine.api import search
# Index name for your search documents
_INDEX_NAME = 'search-www-simoahava-com'
def create_document(title, uri, description, tags, content):
"""Create a search document with ID generated from the post title"""
doc_id = re.sub('[\s+]', '', title)
document = search.Document(
doc_id=doc_id,
fields=[
search.TextField(name='title', value=title),
search.TextField(name='uri', value=uri),
search.TextField(name='description', value=description),
search.TextField(name='tags', value=json.dumps(tags)),
search.TextField(name='content', value=content)
]
)
return document
def add_document_to_index(document):
index = search.Index(_INDEX_NAME)
index.put(document)
class BaseHandler(webapp2.RequestHandler):
"""The other handlers inherit from this class. Provides some helper methods
for rendering a template."""
@webapp2.cached_property
def jinja2(self):
return jinja2.get_jinja2(app=self.app)
class ProcessQuery(BaseHandler):
"""Handles search requests for comments."""
def get(self):
"""Handles a get request with a query."""
uri = urlparse(self.request.uri)
query = ''
if uri.query:
query = parse_qs(uri.query)
query = query['q'][0]
index = search.Index(_INDEX_NAME)
compiled_query = search.Query(
query_string=json.dumps(query),
options=search.QueryOptions(
sort_options=search.SortOptions(match_scorer=search.MatchScorer()),
limit=1000,
returned_fields=['title', 'uri', 'description']
)
)
results = index.search(compiled_query)
json_results = {
'results': [],
'query': json.dumps(query)
}
for document in results.results:
search_result = {}
for field in document.fields:
search_result[field.name] = field.value
json_results['results'].append(search_result)
self.response.headers.add('Access-Control-Allow-Origin', 'https://www.simoahava.com')
self.response.write(json.dumps(json_results))
class UpdateIndex(BaseHandler):
"""Updates the index using index.json"""
def get(self):
with open('index.json') as json_file:
data = json.load(json_file)
for post in data:
title = post.get('title', '')
uri = post.get('uri', '')
description = post.get('description', '')
tags = post.get('tags', [])
content = post.get('content', '')
doc = create_document(title, uri, description, tags, content)
add_document_to_index(doc)
application = webapp2.WSGIApplication(
[('/', ProcessQuery),
('/update', UpdateIndex)],
debug=True)At the very end, I’m binding requests to the / endpoint to ProcessQuery, and requests to /update to UpdateIndex. In other words, these are the two endpoints I am serving.
UpdateIndex loads the index.json file, and for every single content piece within (blog posts, pages, etc.), it grabs the title, uri, description, tags, and content parameters from the content JSON, and creates documents for each instance. Then, each document is added to the index.
This is how the Search API can be used to translate any JSON file into a valid search index, that you can then build queries against.
Queries are made by polling the /?q=<keyword> endpoint, where keyword matches a valid query against the Search API query engine. Each query is processed by ProcessQuery, which takes the query term, polls the search index with that term, and then compiles a result of all the documents that the search index returns for that query (in ranked order). This result is then pushed into a JSON response back to the client.
The search API gives you plenty of room to optimize the index and for compiling complex queries. I’ve opted for a fairly mundane approach, which might lead to some odd ranking outliers, such as documents that should clearly be at the top of a list of relevant results ending up in the end, but I’m still quite happy with how the robustness of the API.
4. The JavaScript
Finally, I need some client-side code to produce the search results page. Since Hugo doesn’t have a web server, I can’t do the search server-side - it must be done in the client. This is one of the cases where a static site loses some of its shine when compared to its counterparts that come equipped with a web server and server-side processing capabilities. A Hugo site is built and deployed all at once, so there’s no dynamic generation of HTML pages after building - everything has to happen in the client.
Anyway, the search form on my site is very simple. It just looks like this:
<form id="search" action="/search/">
<input name="q" type="text" class="form-control input--xlarge" placeholder="Search blog..." autocomplete="off">
</form>When the form is submitted, it does a GET request to the /search/ page on my site, adding whatever was typed into the field as the q query parameter, so the URL becomes something like
https://www.simoahava.com/search/?q=google+tag+manager
On the /search/ page, I have a loading spinner which waits until the request to the search endpoint is completed. The search call is done with JavaScript, and it looks like this:
(function($) {
var printSearchResults = function(results) {
// Update the page DOM with the search results...
};
var endpoint = 'https://search-www-simoahava-com.appspot.com';
var getQuery = function() {
if (window.location.search.length === 0 || !/(\?|&)q=/.test(window.location.search)) {
return undefined;
}
var parts = window.location.search.substring(1).split('&');
var query = parts.map(function(part) {
var temp = part.split('=');
return temp[0] === 'q' ? temp[1] : false;
});
return query[0] || undefined;
};
$(document).ready(function() {
var query = getQuery();
if (typeof query === 'undefined') {
printSearchResults();
return;
} else {
$.get(endpoint + '?q=' + query, function(data) {
printSearchResults(JSON.parse(data));
});
}
});
})(window.jQuery)To keep things simple, I’ve only included the relevant pieces of code that can be used elsewhere, too. In short, when the /search/ page is loaded, whatever is included as the value of the q query parameter is immediately sent to the search API endpoint. The response is then processed and built into a search results page.
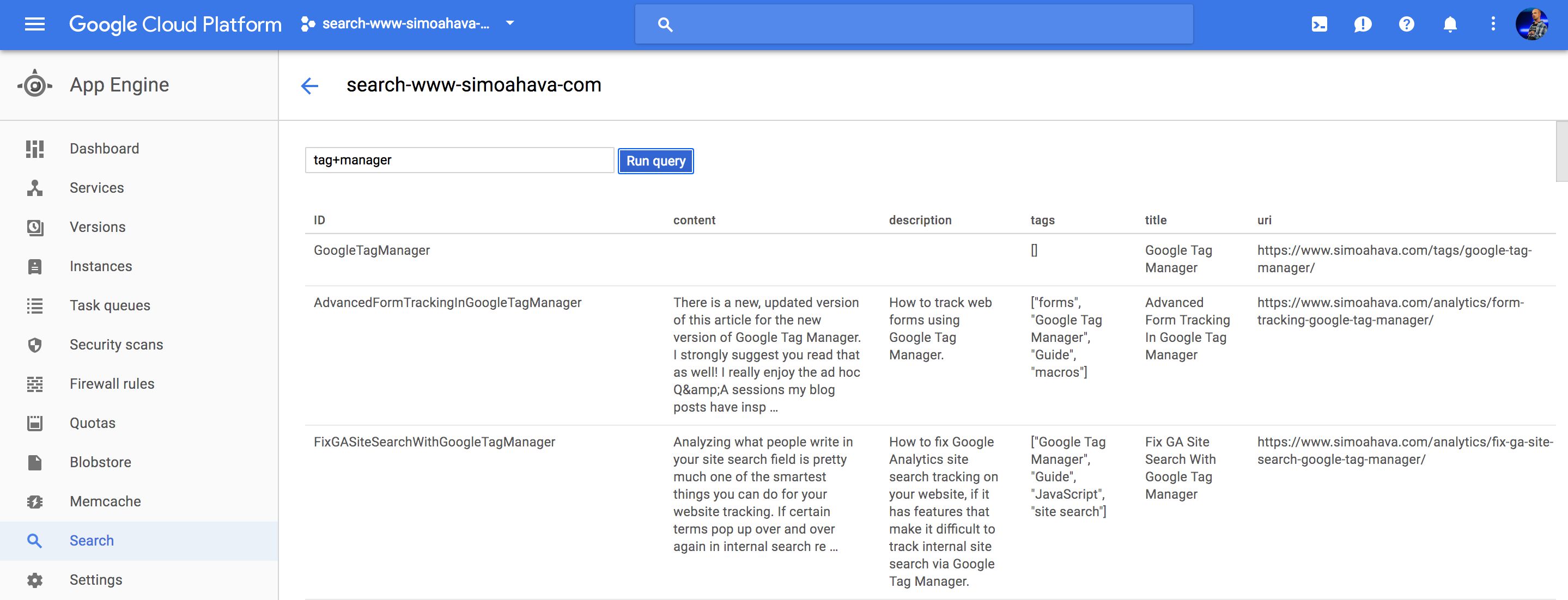
So, if the page URL is https://www.simoahava.com/search/?q=google+tag.manager, this piece of JavaScript turns that into a GET request to https://search-www-simoahava-com.appspot.com/?q=google+tag+manager. You can visit that URL to see what the response looks like.
This response is the processed, and the search results page is built.
Summary
This is how I’ve chosen to build site search using the flexibility of Hugo together with the powerful Search API offered by Google’s App Engine.
Based on my limited amount of research, it’s as good a solution as any, and it seems quite fast without compromising the power of the search query engine. However, as more content builds up, it’s conceivable that the query engine either gets slower or I start hitting my free tier quotas, at which point I’ll need to rethink my approach.
The weak link at the moment is that everything is done client-side. That means that contrary to the philosphy of static sites, a lot of processing takes place in the browser. But I’m not sure how this could be avoided, since a static site doesn’t offer you the capabilities of a server-side processor.
At this time, it’s a trade-off I’m willing to make, but I am anxious to hear feedback if the search is clumsy or not working properly for you.