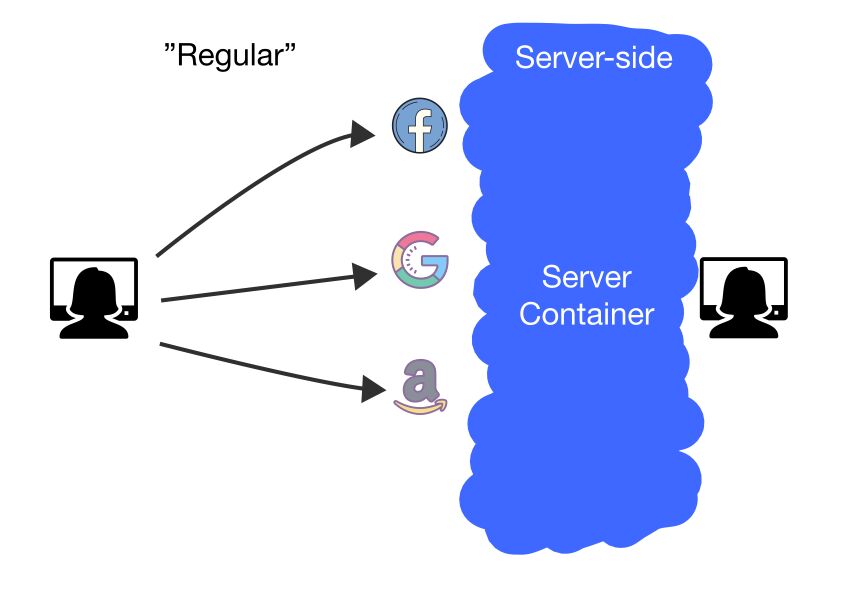
I have been a strong supporter of server-side tagging, in particular Google’s server-side tag management solution.
I admire the way it seeks to readjust the balance of control that typically has been in favor of the marketing vendors whose JavaScript libraries have been free to wreak havoc in the user’s browser.
{kind=link}
By inserting a buffer between the user and the vendor, the owner of the server-side tagging setup can take control over what data the marketing vendors can actually process of the user.
However, for all the good it brings to an organization, there are still some unsolved problems with the technology.
Unfortunately, these problems aren’t things that a server-side tag management solution could solve in isolation.
{kind=link}
In this article, I explore these problems with the purpose of inspiring discussion and, hopefully, more focus on features that would help with the trifecta of user agency, transparency of data flows, and control over what is processed by the server-side proxy.
The Simmer Newsletter
Follow this link to subscribe to the Simmer Newsletter! Stay up-to-date with the latest content from Simo Ahava and the Simmer online course platform.
Agency: The user should have the final say
TL;DR By making ad blockers less efficient, server-side tagging erodes the user’s agency over their browsing experience!
If you LARP as a fly in the ceiling in any sales or implementation pitch around server-side tagging, you’ll soon hear what many consider to be the most persuasive argument:
By running behind a custom domain name, server-side tagging can be used to avoid ad and content blockers from interfering with data collection.
I’ll be using the term ad blocker to conflate all different types of ad/content/privacy blockers in the rest of the article copy.
This is an undeniable outcome of replacing direct communications with vendor domains (e.g. facebook.com) with a custom subdomain of the company’s main web property (e.g. sgtm.mycompany.com).
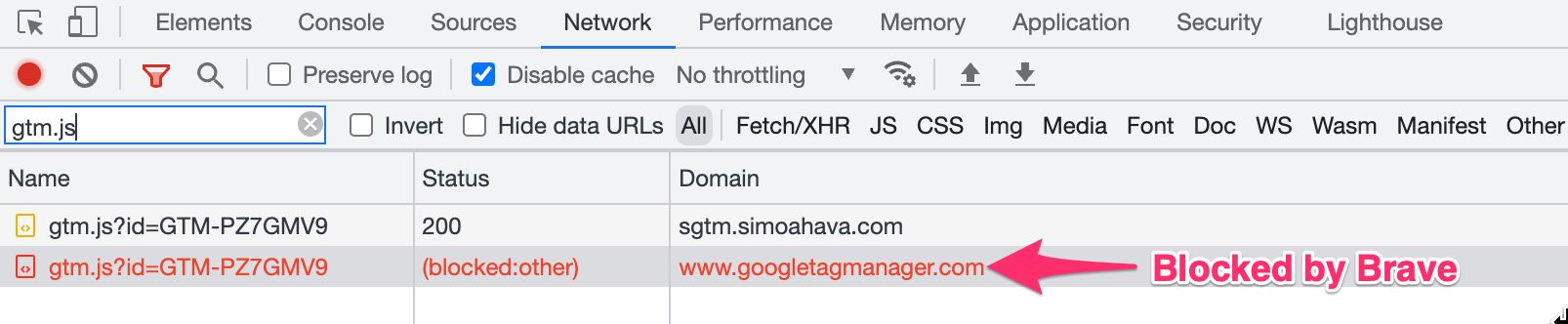
Many blockers still use heuristics that primarily look at the URLs that receive network requests from the user’s browser. If these URLs match patterns in their blocklists, the network requests are denied.
By moving away from facebook.com to sgtm.mycompany.com, a key part of the pattern is obfuscated. It’s very unlikely for a blocklist to have mycompany.com, whereas it’s almost certain ad blockers recognize facebook.com.
{kind=link}
Yes, many blockers also look into other parts of the request such as the path or query parameters, but these are easy enough to obfuscate with the server-side tagging technology, too.
Whether you do this intentionally (you actually want to prevent ad blockers from doing their job) or unintentionally (you want to move your data collection to first-party and blocking ad blockers is just a side effect of this), you need to respect the user’s technology choices when engineering data collection.
You have no way of knowing why the user is using an ad blocker.
They might use it because they don’t want to be tracked.
They might use it because they don’t want to see ads.
They might use it because they want the Web to be faster.
They might use it without knowing they’re using it, if they happen to use a browser such as Brave that has built-in ad blocker functionality.
Why is this a difficult problem to solve?
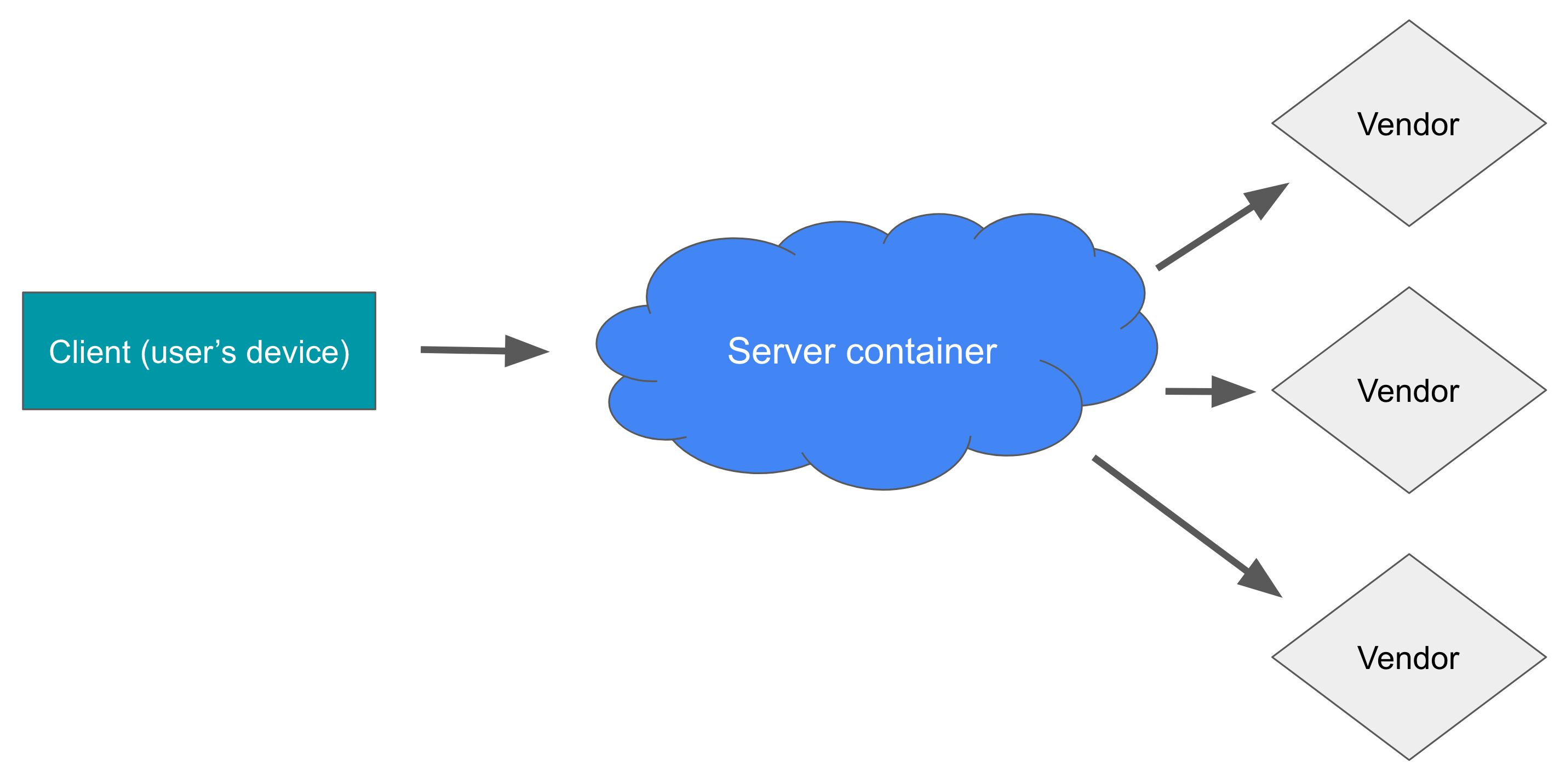
One of the main benefits of server-side tagging is data stream consolidation. You can reduce client-side performance woes and mitigate the privileges given to vendor JavaScript libraries by only collecting a single stream of data from the user’s device to the server-side tagging endpoint.
The server then takes this stream and fans it out to the marketing vendors. This way a single Google Analytics 4 stream, for example, can be used to also collect data for Facebook, for Google Ads, for Taboola, etc.
{kind=link}
So now if the user is using an extension that blocks Facebook but not Google Analytics, you need to first check if the user’s browser would block the Facebook stream, then pass this information to the server with the GA4 hit, and then in the server make sure the Facebook stream is blocked so that the user’s choice is respected.
This is awkward.
Your site might also have a Content Security Policy in place which prevents you from making the mock request to facebook.com in order to check if it would be blocked by an extension.
What are the potential solutions?
Ad blockers could expose in a standardized way which vendors or endpoints are currently being blocked, shimmed, or restricted in some other way in the browser. The website could read this information and then use it to engineer the triggers in the server. However, I’m not sure ad blockers can agree on a standard like that, and I don’t think they are willing to even pursue it, as the same information could be used to avoid the ad blocker’s heuristics even more efficiently.
The website could do a simple check (e.g. with a dummy
ads.jsfile) if the user is using any type of ad blocker, and then the site could proactively block the entire data flow to the server container. This is a drastic measure, of course, because the server-side tagging setup can be used for many things that are completely unrelated to tracking, ads, or the types of things that ad blockers typically target.Same as the previous approach but instead of blocking the entire flow, the website could classify which flows are typically blocked by ad blockers and only prevent those from activating if the user is using an ad blocker. This is problematic because there is no standardized classification of what different ad blockers can do.
The decision about proactively blocking data flows could be tied to mechanisms like the Global Privacy Control and the notion of “consent” under GDPR and the ePrivacy Directive, for example. But this is problematic because some of the justifications for using an ad blocker have nothing to do with personal data or user data or legal regulation.
In this, the more proactive you can be, the better. If it’s possible to block the flows that would typically be targeted by an ad blocker, do so. You’ll also mitigate your risks of collecting data that you should not be allowed to collect in the first place.
Transparency: The Vegas Rule of server-side tagging
TL;DR Moving data flows server-side makes it more difficult to validate if the data is collected and processed legally and according to the user’s wishes and choices.
The Vegas Rule of server-side tagging goes like this:
What happens in the server, stays in the server.
This is a cornerstone of the client-server architecture of the Internet. There’s no obligation for one to reveal anything to the other beyond what is dispatched in the requests and responses that flow between the two.
This also poses a major problem to replacing client-side tagging with server-side tagging (to a certain degree).
One of the benefits of keeping the data flows in the browser (or user’s device) is that they can be monitored and audited in place.
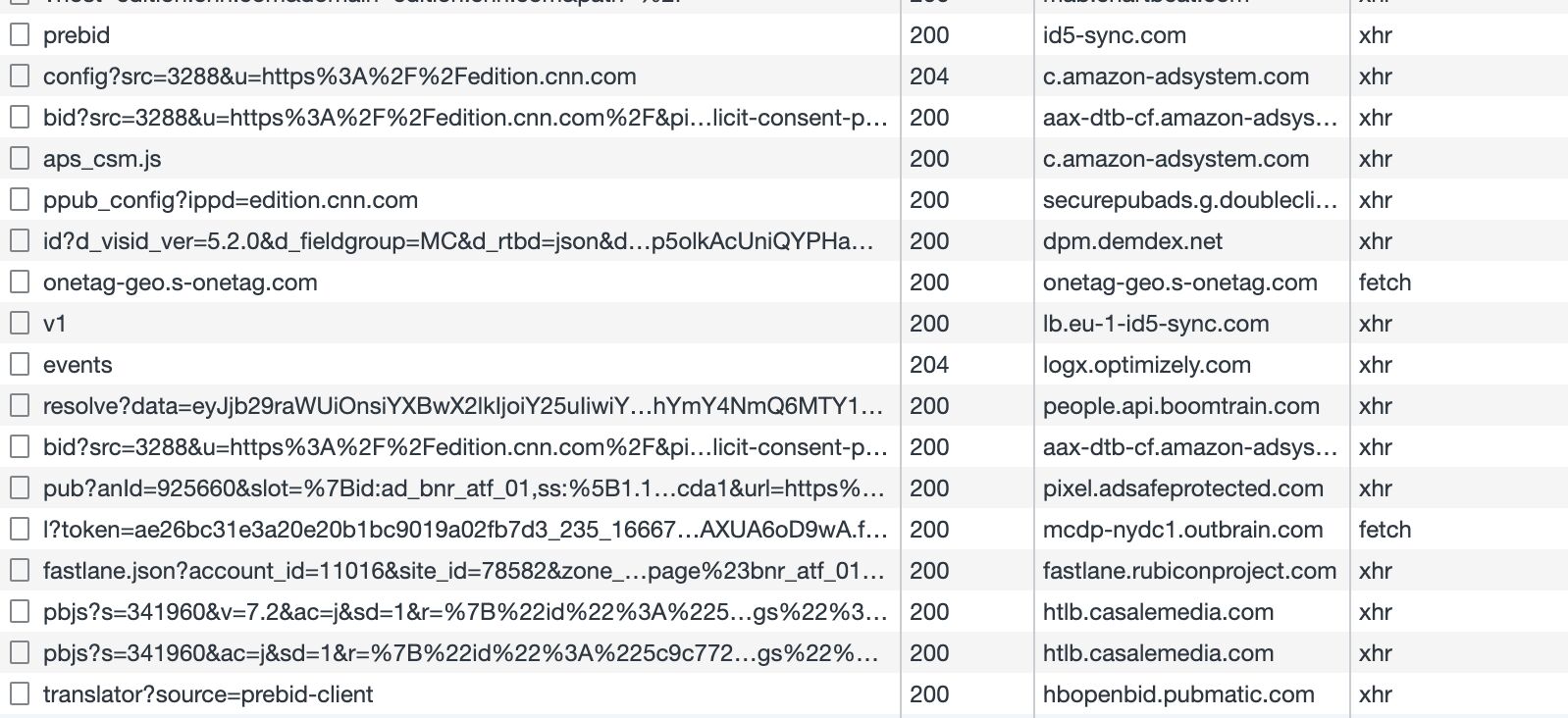{kind=link}
No, most Web users do not have the skills or tools to do this type of auditing, but there are numerous organizations and countless individuals who do this work on the “typical” web user’s behalf.
For example, if a website asks for the user’s consent to access information stored on the device (under the auspices of the ePrivacy Directive, for example), it’s easy enough to monitor the data flows in the browser to see if they make use of device storage.
If this logic is moved to the server, this transparency is lost.
This is not a novel problem! Any time data processing happens outside the browser, such as in the company CRM or in a vendor’s service, the user can only trust (or hope) that their choices and rights are being observed.
But as the whole point of server-side tagging is to move data flows from client-side to server-side, this problem is magnified beyond anything that we’ve seen before.
Why is this a difficult problem to solve?
The main challenge here is that there is no existing mechanism for revealing server-side machinations in the user’s device. There is no audit tool the user can launch in the web browser, for example, which would show what happens to the data flows once they depart the user’s device.
And even if there was some tool like that, the server can freely choose what information to divulge back to the request origin. So there’s no way of trusting that the information is an accurate reflection of what happened in the server, and the company running the server might have good reason to obfuscate some of the information, especially if it pertains to sensitive business data.
What are the potential solutions?
The server-side tagging vendor (Google, for example), could build into the application a mechanism that reports back to the request origin (in the HTTP response) what happened in the server environment. A tool like Tag Assistant could then read this and report it to the user. The main problem with this approach is the increase in network egress costs, as the HTTP response size increases with this new metadata. Additionally, this requires the user (or the person doing the auditing) to install a browser extension and trust the data it reveals.
The company running the server container should clearly document what types of data flows take place on the website and in the server. However, there’s no reason for the user to believe this document is accurate, consistently updated, or that it reflects the status quo with the user’s interests in mind.
The server-side tagging application could enable a public-facing “audit view” that savvy users could load in order to see what happens within the server container. However, this could lead to problems where the company wants to hide some of that information due to it being business-critical or otherwise sensitive. This would also result in increased costs for the company, as the public-facing web service would need to be maintained and supported by the server environment.
For now, the best approach is to be as proactive as possible in describing the data flows that happen in the server. It’s also very important to understand that just because something can’t be audited doesn’t mean it’s out of reach of legal compliance.
In the European Union, for example, you have a legal obligation to respect the right to privacy for EU data subjects, and moving your data flows to the server doesn’t exempt you from this.
Transparency is a proactive trait when it comes to server-side data flows. You should go out of your way to make sure your visitors and customers feel (and know) their right to control their personal data is respected.
Control: There’s no such thing as “too much granularity”
When it comes to control, the company running the server-side tagging environment should have complete and total say over what happens in the server environment.
That is the only way they can truly respect the user’s agency and the need for more transparency.
As such, the notion of control trumps all other aspects of server-side tagging. If control is compromised, the whole raison d’être of server-side tagging falls apart.
This is something that Google’s server-side tag management solution does not currently provide to a satisfactory degree.
{kind=link}
For example, the built-in templates in the container (the Google Analytics 4 template, for one), are not open-sourced nor can they be opened in the custom template editor.
This means that even though you have control over the data flow from the client to the server, you lack the ability to control or validate what happens to this data before it’s dispatched to the vendors.
Similarly, you might find the need to control how the incoming network request is parsed into an “event data object” that the tags can digest. Unfortunately, there’s no way to interject code into the process where the server container parses an incoming request and processes it for tags.
Most of the ad hoc controls you have when running a server-side GTM instance are not granular enough.
For example, you can configure a policy that determines what APIs the server container’s templates can use (can they, for example, set cookies or send HTTP requests). But you can’t do this on a tag-by-tag basis without editing the templates.
So even though I celebrate control as the ultimate gift of setting up a server-side tagging environment, much of this control is still an illusion.
Why is this a difficult problem to solve?
Actually, I don’t think this is a difficult problem to solve, and I’m confidently hopeful that Google will work towards improving this in the (near) future.
Control in a server-side tagging environment is a pie that is shared with many hungry participants.
Google as the service vendor has control over how the service works.
The company running the server has control over how the data flows are configured.
The user whose data is collected has (or should have) control over what data of theirs is processed.
Marketing technology vendors gain control when they create templates and server-side endpoints for data collection.
Ultimately, the company that runs the server should have final say over how this control is distributed.
What are the potential solutions
If we agree that the control over the server-side environment should be governed by the company that runs/owns the server, we arrive at the following consequences:
Google needs to provide a service that has enough granular toggles for controlling all aspects of the data flow. This means proper request handling, event data management, tag-by-tag permission controls, consent APIs, storage access control, and so forth.
Marketing technology vendors need to create templates that do not require data collection beyond the absolute minimum required to run a service. Many companies are asking for highly sensitive and sticky personal data (such as email addresses) to be delivered through server-to-server calls. This is very risky, and marketing vendors should proactively seek to minimize this type of data collection.
Server container admins need to learn how the tag management solution itself works and how the Cloud environment that hosts the service is configured. The latter is especially poignant – server-side tagging is, for many, the first touchpoint with a scalable Cloud service. This comes with an enormous learning curve that many admins are not prepared to tackle.
Regular Internet users need education about these types of technologies so that they can better prepare to manage the data collected from their browsers and devices. This is of course a tall order, and it should never be the responsibility of the user to learn something as a prevention measure. If that is the outcome, then the data collection should be strictly opt-in.
The word control has no positive or negative connotations by default. Server-side tagging is all about control, but it’s the mutual understanding between the parties listed above whether this control is used for good or for evil.
Summary
The technology of server-side tagging frustrates me to no end.
One the one hand, I’m incredibly excited about its prospects. It delivers so many benefits to organizations that want to take better care of their users, better care of their data flows, and better care of the relationships they have with their marketing vendors.
On the other hand, it’s crippled by the limitations of the online environment it works in. The client-server architecture of the Internet is resilient to modern requirements (or expectations) of transparency. The push for first-party data collection (which can be considered a net positive thing) means that traditional controls users have for data flow management (e.g. ad blockers) are less efficient.
I don’t know if others share these views, but in my opinion, the suggestions I propose in this article should result in a universally better environment for all parties involved.
For those that want to do no evil, supporting user agency, choosing transparency over opaqueness, and increasing granularity of control should be priorities when developing the online environment towards a healthier status quo.