10 JavaScript Concepts For Web Analytics Implementation
I’ve already written extensively about JavaScript in web analytics implementation. Suffice to say, understanding at least the basics is absolutely necessary to survive in the technical medium of the web browser.

This article expands on a conference talk I gave at MeasureCamp IX, London a short while ago. I’ve always been quite single-minded about the importance of JavaScript in web analytics development, and it was a pleasure for me to get some of that off my chest. So I want to go over the ten concepts introduced in my conference talk with a little more detail, especially in the context of Google Tag Manager.

The Simmer Newsletter
Subscribe to the Simmer newsletter to get the latest news and content from Simo Ahava into your email inbox!
Get the basics right
JavaScript is not the quirky animation tool from two decades ago anymore - it’s a programming language if there ever was one. It hides a lot of complexity under its seemingly simple syntax, though in the web browser much of this complexity is either abstracted or removed entirely thanks to how the client-server infrastructure of the web works.
To get up to speed with JavaScript, I typically recommend the following resources. Codecademy especially is something you might want to devote time and effort to. It has lots of different tracks, and some that are extremely useful for web (analytics) developers.
1. Codecademy

Codecademy is an amazing resource. The courses are free, fully interactive, and the service keeps track of your progress as you learn new skills along the way. Codecademy has lots of tracks for web developers, but I want to highlight the following as the bare minimum for web analytics:
I recommend making it habitual to always have a course active in Codecademy. Programming is not a skill you develop in silos - each new language and discipline you learn helps you become a better developer overall.
2. Books

You might argue that books are not the best way to keep up-to-date with web technologies, but the following volumes have stood the test of time (with the exception of the last one which is brand new) marvellously, and even if some of the code samples might be outdated, the ideas behind the solutions remain as topical as ever.
Nicholas Zakas: Professional JavaScript for Web Developers (3rd Edition)
Jonathan Weber: Practical Google Analytics and Google Tag Manager for Developers
Zakas’ volume is a great, if somewhat intimidating, foray into how JavaScript and the web browser interact. Needless to say, it is a goldmine for understanding the technical stack you’re working with when implementing web analytics solution. It’s the book I would most recommend you to read once you have the basics of JavaScript down.
3. Sandbox
The only way you can really learn something is by doing it. All creative skills, programming included, need honing. The best way to learn programming is to actively practice it. So in addition to taking courses and learning by reading, remember to also create stuff! A great way to do it is to deploy Google Tag Manager on your own website. If you don’t have one, you can now create one with your new-fangled skills!
Play around with the JavaScript Console of your web browser’s developer tools. Implement scripts in Google Tag Manager, and see how they interact with your website. Use tools like JS Lint to understand what issues your code might have.
Whatever you do, just keep coding.

In the context of Google Tag Manager, functions are arguably the most useful little things when customizing implementations. That’s because the Custom JavaScript Variable is basically a function call that you use to resolve a value.
The Custom JavaScript Variable has a very deliberate syntax when using Google Tag Manager, and some of the restrictions might sound odd to you, so I want to go over them with some detail in this chapter.
Anonymous function with a return statement
The Custom JavaScript Variable requires an anonymous function with a return statement. An anonymous function is exactly that: it’s a function without a named identifier that you could use to refer to it. Now, you can argue that it does have a name since the Variable itself has a name, but that’s GTM’s proprietary way of resolving the Custom JavaScript Variable and has nothing to do with the underlying JavaScript syntax.
The Custom JavaScript Variable doesn’t take any parameters, either. All values you want to process through it need to come from the internal data model of Google Tag Manager (GTM’s “Variables”), need to be created on the spot (local scope), or need to be available in the global namespace (global scope).
Finally, all Custom JavaScript Variables need a return statement. They must always return some value, as they are invoked in situations where a value is required.
So this is the minimum viable Custom JavaScript Variable you could create.
function() {
return;
}When invoked with the {{Variable}} syntax, this function would return undefined.
Avoid side effects
Since the Custom JavaScript Variable is a value-returning function which does not accept parameters, it should only be used for input/output operations. Thus, the purpose of the Custom JavaScript Variable is to take some value, modify it, and then return the modified value.
A function has side effects if it does something else except the input/output operation described in the previous paragraph. Typical side effects occur when a function is used to modify something in the global scope, or it’s used to set some value elsewhere, or, in the context of Google Tag Manager, it’s used to manipulate the Data Layer.
You should avoid side effects because Google Tag Manager can’t guarantee that the Custom JavaScript Variable is only resolved once per activation. In fact, in Preview mode, Custom JavaScript Variables can be resolved dozens of times per dataLayer.push(), which can lead to a confusing experience.
function() {
// AVOID THIS:
window.dataLayer.push({'event' : 'JavaScript executed'});
return;
}The main problem with side effects is that they’re hard to trace if problems arise. Since the Custom JavaScript Variables are resolved at arbitrary times, having them modify the global scope can be hazardous and can easily lead to unwanted race conditions.
Understand scope, utilize closures
JavaScript in the web has two types of scope: local and global.
Local scope, also known as function scope, is what variables are restricted to when declared within a function. When you declare a variable in a function, it will only exist for the duration of the function call (though see the part about closures below), after which the garbage collector comes and whisks it away. Locally scoped variables cannot be referred to or invoked from outside the current function context.
function() {
// These variables all have local scope
var hello = "Hi, ";
var myname = "Simo!";
return hello + myname;
}Global scope, on the other hand, comprises variables that are declared as properties of the window object. If you don’t use the var keyword when declaring a variable in a function, it is automatically elevated into global scope.
When a variable is in global scope, you can refer to it anywhere. For example, the ubiquitous document property of the browser’s Document Object Model can be used anywhere since it’s actually a global property of the window object:
window.document === document; // true
Closures are an exception to how locally scoped variables are ephemeral and inaccessible from the outside. When you create a closure, you are actually creating a simple interface that lets you access the locally scoped variable from outside the function!
function() {
var timeNow = new Date(); // Locally scoped
return function() {
return "Time then was: " + timeNow;
};
}The closure is the return function() {...} statement. Because the function is declared within same context, it has access to the locally scoped timeNow variable. And because the function is the target of the return statement, you can actually call this returned function in code! In the example below, the Custom JavaScript Variable we just created above is named Time Then.
var timeThen = {{Time Then}}();
console.log(timeThen);The parentheses at the end of the Custom JavaScript Variable are significant. If you simply had {{Time Then}}, the variable assignment would store the return value of the Custom JavaScript Variable (the closure) into the timeThen variable. The console.log() command would simply output the function description itself, and not the result. By adding the parentheses, you’re telling the browser to actually invoke the function returned by the Custom JavaScript Variable. Since the timeNow is only created once (when the Custom JavaScript Variable is first resolved), the closure will always return the same date-time string.
Modify state when you are in control of resolution
There is one exception to Custom JavaScript Variables having side effects. When you are in full control of when the function is resolved, it’s fine to cause side effects, since you don’t have to worry about the function resolving an unknown number of times or in unknown contexts.
One such example is when using a closure in a callback. Callbacks (more on these later) are execution milestones which take place after some other process has completed. So if you indicate the closure of a Custom JavaScript Variable as the value of a callback, you can rest assured that the function is only called once - when the main process has completed.
function() {
// Return a function to be used by hitCallback
return function() {
// It's OK to modify state here!
window.dataLayer.push({'event' : 'tagHasFired'});
};
}This process is exemplified in the hitCallback feature of the Google Analytics tracker. The hitCallback function is called after the request to Google Analytics has completed. Thus, you can use the closure of a Custom JavaScript Variable to perform some state-altering thing in the hitCallback field itself! This is very useful if you want to chain tags in a sequence, for example.
FURTHER READING
Take a look at the following articles for more information on how functions work:

In JavaScript, you have five value-carrying data types:
var something = 5; // number
var something = "five"; // string
var something = true; // boolean
var something = {five: 5}; // object
var something = function() { return 5; }; // function
It gets slightly messier than this, since there are actually lots of different types of objects (all JavaScript data types are actually an extension of “object” in its fundamental sense):
var something = {five: 5}; // Object
var something = [5,5,5]; // Array
var something = new Date(); // Date
And finally we have some mystic pseudo-types which don’t carry any value:
var something = undefined; // undefined
var something = null; // null
Dynamic type
Unlike some other programming languages (e.g. Java), type is dynamic in JavaScript. That means that you can reassign a variable with a completely different type without having to worry about type conversion.
var something = 5;
something = "five";The above is possible in JavaScript, because the variable assignment itself doesn’t coerce the assigned value to any specific type. This can be a weakness in the code, because it requires you to test for type to avoid errors.
// Works because something is a number
var something = 5;
var somethingMultiplied = something * 2;
// Won't work because something is suddenly a string
something = "five";
somethingMultiplied = something * 2; // NaN: Not a Number
// So you need to test
if (typeof something === 'number') {
somethingMultiplied = something * 2;
}The further apart your variables are from their execution context, the messier it can get with all the type checks. So try to avoid exploiting dynamic type, and do your best to maintain type when creating and reassigning variables.
Loose type
JavaScript also does type conversion for you when needed. This means that the following is possible:
var something = "5";
var somethingMultiplied = something * 2; // 10
In the multiplication, JavaScript expects something to resolve to the number type. Even though something is a string, JavaScript detects the number within and automatically converts the variable to a number for the multiplication statement. The variable something itself is not modified, but the value held by it is converted automatically to make resolving somethingMultiplied possible.
Note that there are some embarrassing exceptions. The plus operator (+) is not only used for mathematical statements but also for concatenating strings. So if you try to add a number to a string, you’ll end up with a concatenated string rather than a number!
var a = "5";
var b = 6;
var c = a + b; // "56"!
// You need to use parseInt() to manually convert to number:
c = parseInt(a) + b; // 11
Weird stuff
I’ll just leave this list here. It’s just a handful off the odd behavior you get when working with loose and dynamic type.
typeof NaN; // number
NaN === NaN; // false
typeof NaN; // number
isNaN(NaN); // true
isNaN(null); // false
typeof null; // object
null instanceof Object; // false
typeof undefined; // undefined
undefined === null; // false
undefined == null; // true
{simo: true} === {simo: true}; // false
Undefined and Google Analytics
Remember that the undefined type has a special function in Google Analytics (and Google Tag Manager). If you refer to a variable which returns undefined, that particular setting, field, or parameter is automatically dropped from the request to Google Analytics.
In Google Tag Manager, undefined can also be used to purge values from the Data Layer. This is extremely useful on single-page apps, where variables persist their values throughout the visit.
window.dataLayer.push({
event: 'GAEvent',
eventData : {
cat: 'Category value',
act: 'Action value',
lab: undefined,
val: undefined
}
});FURTHER READING
The following articles shed more light on data types in JavaScript:

When looking for things that can slow down the site, slow or poorly performing HTTP requests are usually the easy culprit to blame.
Thanks to asynchronous loading, most HTTP requests are done in such a way that they don’t block the page from rendering, but async itself doesn’t guarantee a smooth ride.
Let’s take Google Tag Manager as an example. This is a typical container snippet:
(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({'gtm.start':new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0],j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src='//www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f);})(window,document,'script','dataLayer','GTM-W92WQQ');I’ve gone over this code in an earlier article, but suffice to say that the end result of all this code is this:

In other words, the minified code creates a new script HTML element, which instructs the browser to request for a file in Google’s servers, and the request is done asynchronously.
The script element, then, turns into an HTTP request, since the src attribute in the tag signals the browser to make an HTTP request to the URL value of the attribute.
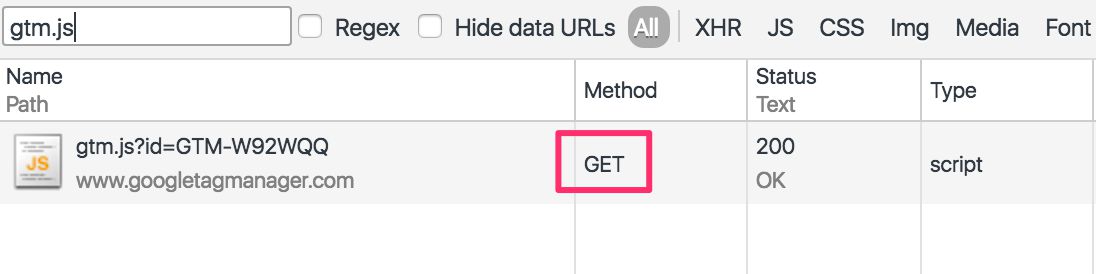
So just by creating the script tag, the browser automatically executed an HTTP request to the given endpoint, and the result of this request is the gtm.js retrieved in the browser for immediate execution.
There are lots of elements that can produce an HTTP request. All scripts, images, and HTML files need to be retrieved from the web server, and the main channel of data transfer is the HTTP request. The following HTML tags (with the given attributes) also invoke HTTP requests:
<input src="url">
<input usemap="url">
<ins cite="url">
<link href="url">
<object classid="url">
<object codebase="url">
<object data="url">
<object usemap="url">
<q cite="url">
<script src="url"></script>
<audio src="url">
<button formaction="url">
<command icon="url">
<embed src="url">
<html manifest="url">
<input formaction="url">
<source src="url">
<video poster="url">
<video src="url">
<a href="url">
<applet codebase="url">
<area href="url">
<base href="url">
<blockquote cite="url">
<body background="url">
<del cite="url">
<form action="url">
<frame longdesc="url">
<frame src="url">
<head profile="url">
<iframe longdesc="url">
<iframe src="url">
<img longdesc="url">
<img src="url">
<img usemap="url">Yeah. That’s quite a bunch.
Note that HTTP requests can be created manually using e.g. XMLHttpRequest or jQuery.ajax(). In fact, when you send hits to Google Analytics, you’re actually using HTTP requests created by the analytics.js library.
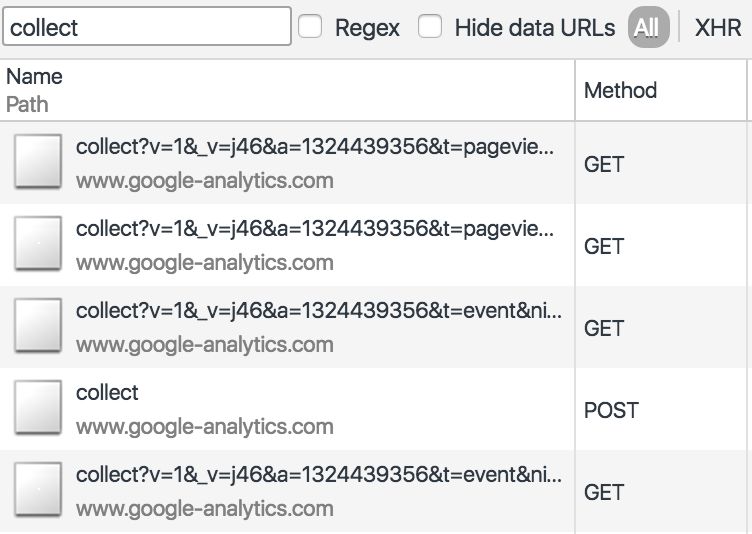
FURTHER READING
Here’s more information on HTTP requests:

The difference between asynchronous and synchronous loading is subtle but significant.
JavaScript in the web browser is single-threaded. That means that only one process can ever be running at a time, and thus every single line of JavaScript must be executed completely before the browser can proceed to the next line. If you make a synchronous HTTP request, it means that the browser will wait until the entire request (download, execution, render) is taken to completion before the browser proceeds to the next line of code in the page. It’s said that synchronous operations are thus blocking.
To counter this potentially devastating blow to page render and user experience, asynchronous loading was introduced to make the “expensive” part of the process, the download, happen so that it doesn’t block the browser.
So, when a request is made asynchronously, the browser initiates the download but then proceeds to the next line of code while the download goes on in the background. Only after the file is completely downloaded, does the browser return execution to this initial process, rendering the downloaded asset in the browser.
The problem with asynchronous execution is that even though you can pinpoint the exact moment when the request is initiated, as it’s governed by the order of the lines of code in the page template, you’ll never know the exact moment when it completes. And this can lead to something called a race condition.
So let’s say I have the following two lines of code in the page template:
<script async src="https://ajax.googleapis.com/ajax/libs/jquery/3.1.0/jquery.min.js"></script>
<script async="" src="https//www.googletagmanager.com/gtm.js?id=GTM-XXXXX"></script>The browser starts loading the jQuery library before GTM, so I might expect jQuery to available to GTM as soon as the latter has finished downloading. But that’s not necessarily the case! The actual download of jQuery can end long after GTM has completed, because the jQuery library is more often than not quite a bulky thing. Also, if the CDN providing the jQuery library has latency, it might affect when jQuery becomes available.
So, if in Google Tag Manager I try to use jQuery, there can be a race condition where GTM expects jQuery to be available but it isn’t.
To combat the race condition, we can use tools like callbacks, promises or, in GTM, Tag Sequencing. You can always resort to synchronous downloading if you’re really concerned about race conditions, but remember that this can have a detrimental impact on user experience.
<!-- Synchronous request -->
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.1.0/jquery.min.js"></script>
<script async="" src="https//www.googletagmanager.com/gtm.js?id=GTM-XXXXX"></script>
<!-- Callback -->
<script>
(function() {
var el = document.createElement('script');
el.src = 'https://ajax.googleapis.com/ajax/libs/jquery/3.1.0/jquery.min.js';
el.async = true;
el.addEventListener('load', function() {
window.dataLayer.push({event: 'jQueryLoaded'});
});
document.head.appendChild(el);
})();
</script>
<!-- Tag Sequencing -->
<script>
(function() {
var el = document.createElement('script');
el.src = 'https://ajax.googleapis.com/ajax/libs/jquery/3.1.0/jquery.min.js';
el.async = true;
el.addEventListener('load', function() {
window['google_tag_maanger'][{{Container ID}}].onHtmlSuccess({{HTML ID}});
});
document.head.appendChild(el);
})();
</script>It’s better to be safe than sorry, so when working with potential race conditions, make sure to always check if the resources you are trying to use actually exist.
if (typeof jQuery !== 'undefined') {
// Use jQuery
} else {
// Use something else
}FURTHER READING
Here are some useful links on race conditions, callbacks, and such.

Single-page web applications (SPA) utilize something called the History API to provide a multi-page experience with only one initial page load in the web server. Subsequent transitions from page-to-page are commonly done using the History API, by withdrawing content from the server without initiating a page refresh, and manually creating history entries in the web browser. Common frameworks for SPAs are e.g. React, AngularJS, and Backbone.js.
SPAs have significant implications for web analytics. For example, an SPA can suffer from the rogue referrer problem, where URL query parameters that are used for campaign settings are overwritten by a subsequent page view hit. For Google Tag Manager, the problem of persistence rears its ugly head, where variables maintain the values you set earlier, leading to these values bleeding into subsequent tags.
Browser history is manipulated because when content is dynamically loaded, the site needs to tell the web browser that the user has entered a new page without the benefit of the page reload doing this automatically. Otherwise you wouldn’t be able to link to dynamic content, nor would the Back and Forward buttons of the browser find your dynamic content.
The two interfaces you’ll run into most often are pushState and replaceState. The former creates a new history entry in the web browser, and the latter replaces the current entry entirely. Here are examples of how to use them:
window.history.pushState(
{pageType: 'formThankYou'},
'Form Success',
'/thank-you/'
);When you run this command, the URL changes to /thank-you/ without a page reload. The first two parameters add additional information about the state. If you now click the Back button of the browser, you are taken to the URL where you called pushState.
window.history.replaceState(
{pageType: 'formThankyou'},
'Form Success',
'/thank-you/'
);When you execute this command, it actually replaces the current page in the browser history. In other words, when you click the browser’s Back button, you are taken to the page you were on before you entered the page from where you called replaceState.
Note that if you simply add #someHash in the URL, it’s the equivalent of calling pushState without the benefit of the other parameters in the interface (e.g. the state object).
In Google Tag Manager, you have a really useful Trigger type called the History Change Trigger. It goes off whenever one of the following History events occur:
- pushState
- replaceState
- hashchange (when the #someHash in the URL appears/changes)
- popstate (when the active history entry changes)
For example, if you want to build pageviews around these history events, it’s quite simple to do with the History Change Trigger!
FURTHER READING
For more information on the Window History API, look no further than these articles:

The web page is stateless. With every page load, the entire page is built from scratch. All the variables, JavaScript libraries, HTML templates, CSS files and other resources are loaded again.
In other words, if the web browser needs to know something, anything, about what happened at any time in the past, you need to manually persist this information.
You can persist the information in the web server, and this is often quite a robust way to do it. However, because of how the web is built, you still need a way of aligning any given web browser (and thus, user) with the requests that are sent to the web server.
The web browser provides a number of ways to persist this information. The most common methods are browser cookies, Web Storage, and IndexedDB.
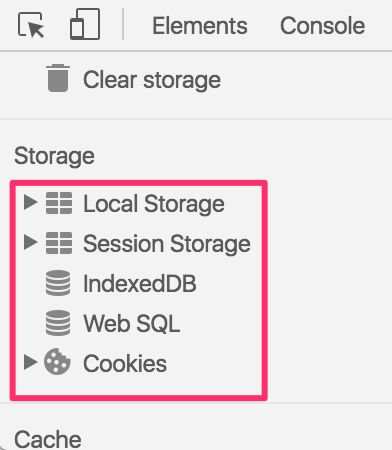
Browser cookies
Browser cookies are useful for simple storage. The browser cookie is essentially a string stored by the web browser, and its accessible only by pages that share the same parent domain to which the cookie was written. So a cookie written on www.simoahava.com would, by default, only be available to pages on www.simoahava.com, but you could also write the cookie on simoahava.com, where it would be available to all subdomains.
A cookie written on simoahava.com would not be available for pages on derekahava.com, because they do not share the same domain.
Cookies also survive transitions from the http:// protocol to https://.
Web Storage
Web Storage (or DOM Storage) encompasses both localStorage (no expiration) and sessionStorage (expires when the web browser is closed). Web Storage is much more flexible than using cookies, because the entries are stored as a hash table, and lookups can be done on a key-by-key basis. With cookies, you need to unravel the entire cookie string just to find the value want.
// TO SET
if (window['Storage']) {
localStorage.setItem('subscribe', 'true');
sessionStorage.setItem('subscribe', 'true');
} else {
setCookie('subscribe', 'true');
}
// TO FETCH
localStorage.getItem('subscribe');
sessionStorage.getItem('subscribe');Note that Web Storage does not survive the transition from http:// to https://. Both protocols have their own storage.
IndexedDB
IndexedDB is much more complex than the aforementioned methods, and is thus more suited for application logic on a much larger scale. For example, if you’re using Service Workers to maintain offline browsing capabilities, IndexedDB is an excellent utility to maintain state while waiting for the internet connection to come back up.
Checkout the link to my article on persisting data in Google Tag Manager for more information (and some tips) on how to setup cookie and Web Storage persistence in GTM!
FURTHER READING
Check out the following links for more information:

Locating elements on the page is one of the more obvious use cases for web analytics. Most commonly we want to know if some specific element was the target of a user action such as a click or form submission.
In Google Tag Manager, identifying an element is easy enough with CSS selectors, but what if we actually want to retrieve some element other than what GTM initially gave us?

There are many ways to retrieve an element relative to some other with JavaScript. A very clumsy way to do it would be to build a complete element chain all between the two elements. So if you wanted to retrieve the element at the top of the DOM in the image above, you could do something like this in a Custom JavaScript Variable:
function() {
// Please don't do this:
return {{Click Element}}
.parentElement
.parentElement
.parentElement
.parentElement
.parentElement;
}But please don’t do this. It’s clumsy and it has multiple points of failure. You’re basically expecting the DOM to have a certain structure without providing any redundancies or fallbacks. The longer the chain, the more sensitive it is to even minor changes to the page markup.A better way is to disregard the actual number of elements, and just climb up the DOM until you reach the very top.
So a more robust way of retrieving the element would be something like this:
function() {
var el = {{Click Element}};
while (el.className !== 'content-sidebar-wrap' && el.tagName !== 'BODY') {
el = el.parentElement;
}
return el.tagName !== 'BODY' ? el : undefined;
}This little script simply climbs up the DOM until it either reaches the element you wanted (.content-sidebar-wrap) or the <body> tag. If it reaches <body>, the assumption is that the element you were looking for was not found, and undefined is returned instead.
Note that this script only works for direct ancestry. If you want to find sibling elements or elements which branch from the direct path between the original element and the root of the document, you might want to leverage frameworks like jQuery to make DOM traversal code more economic.
FURTHER READING
Follow these links to find more information on DOM traversal:

When Google Tag Manager introduced the matches CSS selector Trigger operator a while ago, it eliminated a lot of complexity from validating Triggers to only fire for certain HTML element interactions. In a similar manner, the querySelector and querySelectorAll JavaScript DOM methods were just as impactful when they were introduced some years ago into the web browser API.
If you’ve built websites or worked with CSS (Cascading Style Sheets) styles before, you’ll know what selectors do. They let you select any element or group of elements on the page, and then apply a style to them. For example, the following style declaration would remove the default underline from all links (<a>) with class internal:
a.internal {
text-decoration: none;
}Because it’s such an effective way of selecting HTML elements, it’s not a big surprise that JavaScript introduced methods for using CSS selectors to find and retrieve HTML elements on the page:
// Select every link with attribute data-gtm on the page:
var gtmLinks = document.querySelectorAll('a[data-gtm]');
// Select the first 'h2' element on the page, which is the direct child of 'section'
var firstH2 = document.querySelector('section > h2');
// Select the 'span' with class 'title' that is a descendant of the aforementioned 'h2'
var spanTitle = firstH2.querySelector('span.title');Similarly, if you already have an HTML element, you can use the matches API to check if it matches a specific CSS selector:
var isElementLink = function(el) {
return el.matches('a');
}The function above would return true or false, depending on whether the element passed as a parameter is a link or not. Note that matches isn’t widely supported yet, but there’s a polyfill you can use to make it work across all browsers.
In Google Tag Manager, the matches CSS selector is ridiculously useful. You can use it to fire your Triggers only when a specific element is the target of the interaction. For example, I could configure a Click / All Elements Trigger like the following to make it only fire when the clicked element is a specific <span> (or any of its nested descendants) on the page!
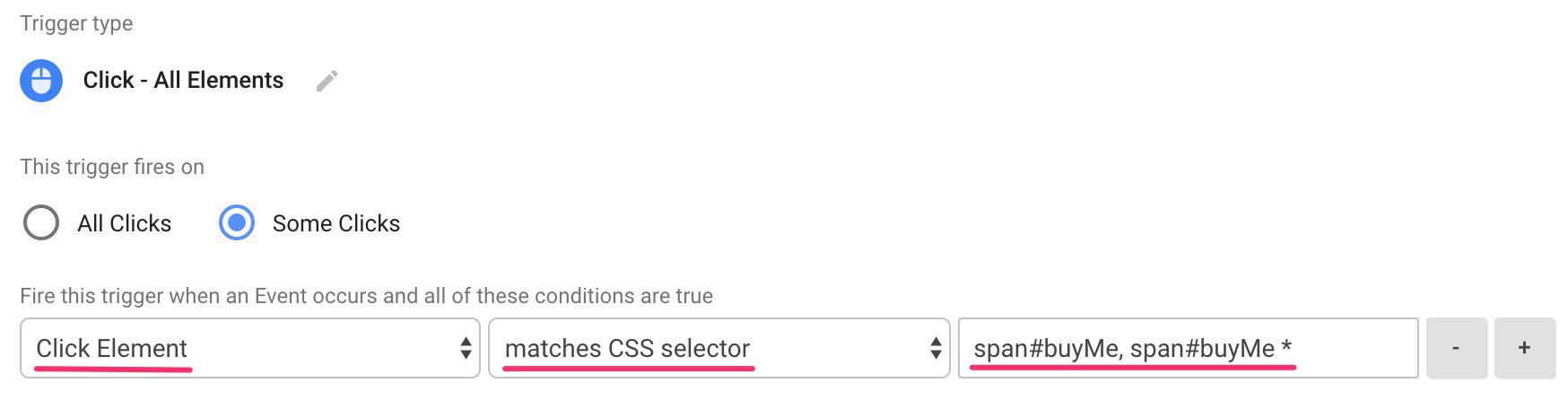
CSS selectors shave a crazy amount of time off your JavaScript, as you don’t have to write clumsy comparison queries using DOM traversal when trying to identify a specific element. Take a look at the further reading links below to learn more about CSS selectors!
FURTHER READING
More stuff about CSS selectors:

jQuery is undoubtedly the most used JavaScript library in the world, and its contributions to standardizing the web experience across browsers and devices should not and do not go unnoticed. The framework provides such a wealth of utilities that trivialize and abstract many of the woes a web developer might have when developing their site to be as accessible across the splintered browser landscape as possible.
In short, jQuery is a library which provides a bunch of simple APIs to perform otherwise complex tasks. For example, let’s take the DOM traversal example from chapter 7 and rewrite it with jQuery:
// Vanilla JS
function() {
var el = {{Click Element}};
while (el.className !== 'content-sidebar-wrap' && el.tagName !== 'BODY') {
el = el.parentElement;
}
return el.tagName !== 'BODY' ? el : undefined;
}
// jQuery
function() {
return jQuery({{Click Element}}).closest('.content-sidebar-wrap')[0];
}So a single line of jQuery abstracted the previous implementation.
Similarly, here’s the difference between building a custom HTTP POST request using regular JavaScript versus using jQuery:
// Vanilla JS
var xhr = new XMLHttpRequest();
var payload = 'v=1&tid=UA-12345-1&t=pageview&dl=https://www.simoahava.com/&cid=12345.12345';
xhr.open('POST', 'https://www.google-analytics.com/collect');
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.onload = function() {
if (xhr.status === 200) {
alert('Yay!');
}
else if (xhr.status !== 200) {
alert('Aww :(');
}
};
xhr.send(encodeURI(payload));
// jQuery
jQuery.post(
'https://www.google-analytics.com/collect',
'v=1&tid=UA-12345-1&t=pageview&dl=https://www.simoahava.com/&cid=12345.12345'
)
.done(function() {
alert('Yay!');
})
.fail(function() {
alert('Aww :(');
});I hope you see the trend here. jQuery really makes things more elegant for both the developer as well as for anyone who wants to look at the code and quickly understand what it tries to do.
jQuery isn’t all-powerful, though, and relying too much on a framework can make your code weak. My suggestion is to always understand what a given jQuery method does before using it. That way you’ll know what the background process is, and you’ll learn to avoid nasty surprises such as how jQuery’s return false; in event handlers can break GTM’s listeners!
Remember also to be wary of race conditions when loading jQuery.

If you load the library asynchronously, it might not be ready by the time you refer to it in your GTM Tags.
FURTHER READING
And here’s the scoop on jQuery:

Finally, the Data Layer. If you’ve used GTM or any tag management solution, it’s probably you’ve had to really put some thought into understanding how tag management solutions leverage the Data Layer to communicate with the website or other digital property.
It’s not purely a JavaScript concept, so it’s kind of a black sheep in this mix. Nevertheless, the most typical implementation of a Data Layer, when it comes to tag management solutions, is an Array-type data structure in the global namespace.
I’ve written about Data Layer quite a lot on this blog, so instead of repeating what I’ve already written far more extensively, I want to direct you to the links below and I strongly suggest you read through them to get a better idea of how the Data Layer works.
FURTHER READING
Be sure to check these links out for more information on the Data Layer:
Summary
The ten JavaScript concepts introduced in this article are, what I consider, the most useful tools that any web analyst would need to know about. Heck, I consider these vital to anyone working with the web, not just analysts!
The thing is, we’re working in an extremely technical medium. The web browser is tantalizingly complex in all its machinations, and it doesn’t really help that all web browsers act slightly differently when it comes to producing the web document into our screens.
When working with web analytics, we are trying to decipher the abstract signals sent by users, web servers, the browser itself, and background processes, as we do our best to align these signals with their real-world counterparts.
It’s not easy!
Trying to deconstruct the enormously difficult concepts of “intent”, “engagement”, and “interaction” using a handful of JavaScript handlers seems like a fool’s errand, but it’s the only thing we can do when creating an implementation framework for any given web application.
But the more we know about JavaScript and the numerous APIs that the web browser lets us tap into, the more we can uncover about our visitors and their actions on the site.
I hope you found these tips useful. Do you have other JavaScript concepts that you consider are absolutely essential for anyone working with the web to acquaint themselves with?
