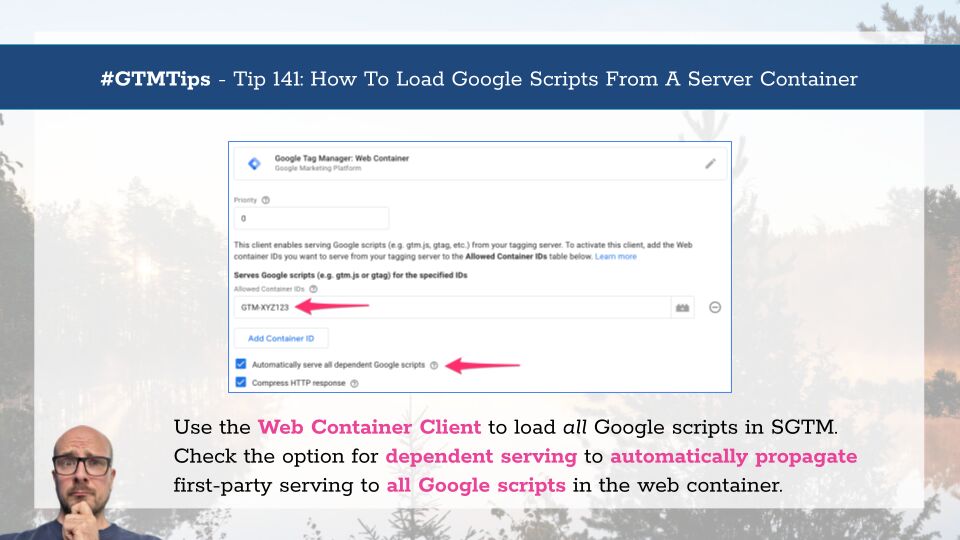
In preparation for the upcoming major integration between Google Tag and Google Tag Manager, Google has rolled out some user interface changes to your GTM containers. The changes simplify the UI quite a bit, with the biggest changes landing on the Overview dashboard and the …