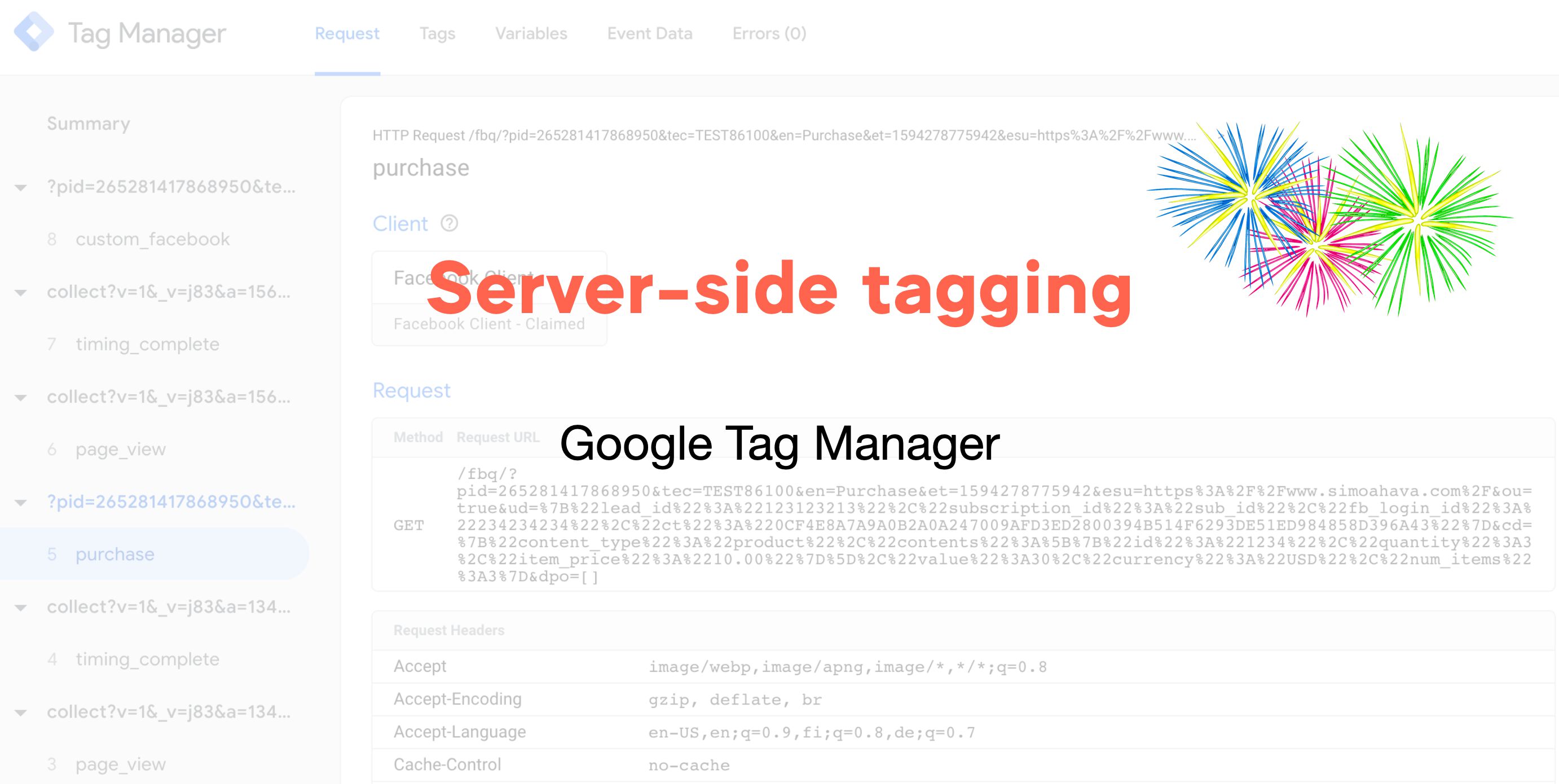
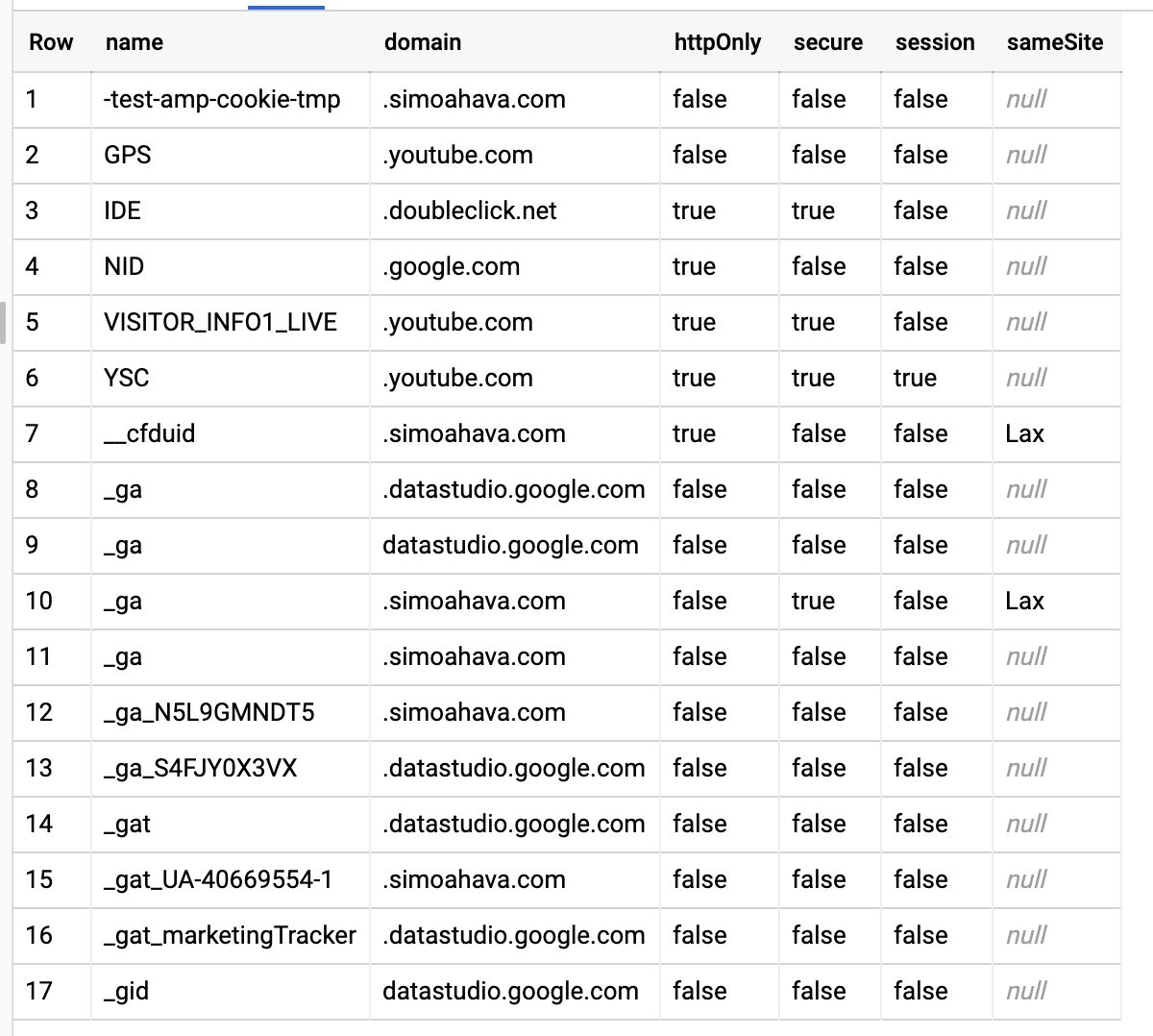
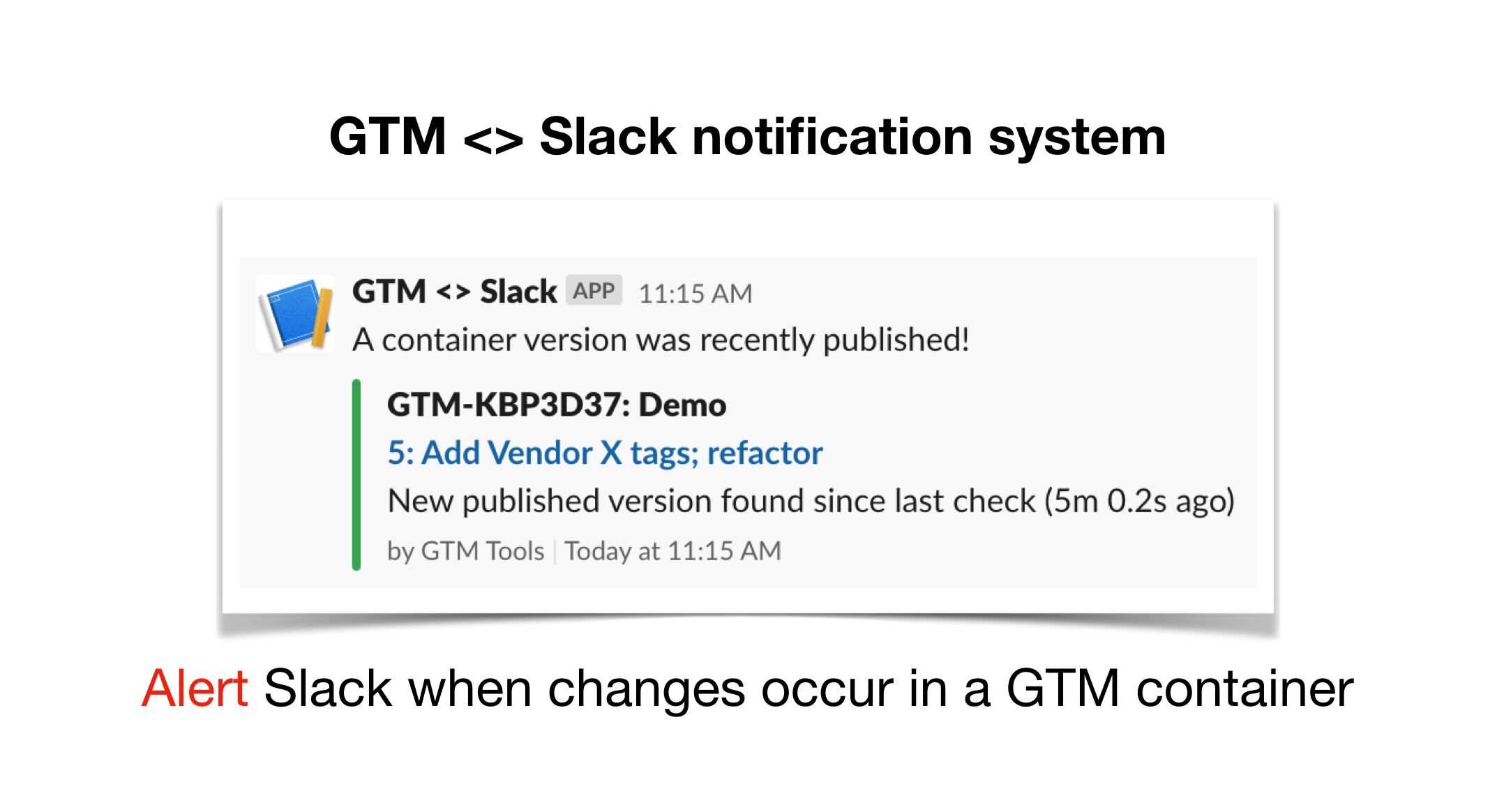
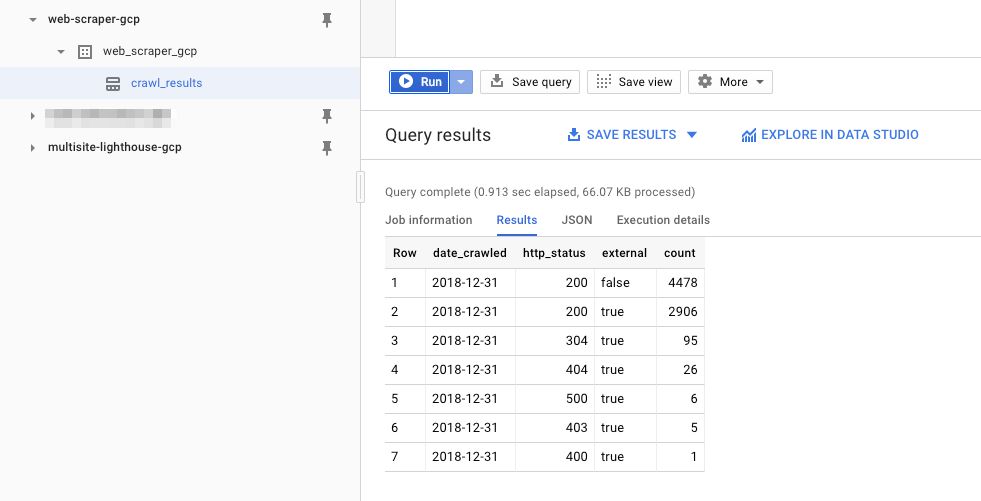
UPDATED 20 March 2026: Shortly after publishing this article, Google Cloud changed how Load Balancer frontend certificate management works. Instead of directly mapping a frontend to a certificate, GCP now wants you to use a certificate map. Luckily, creating one is (fairly) …