User Distributor Custom Tag Template For Google Tag Manager
I’ve enjoyed working with custom templates for Google Tag Manager. A lot. So much so that whenever the need to add some custom code to a container emerges, my first thought is how to turn that into a custom template.
Google has been forthcoming in introducing new APIs steadily, and I think the variety of things you can do with template is improving with every new API release.
In this article, I’ll show you how to use a simple tag template for distributing your users to groups, based on a random split.
You can download and/or install the template here.
XThe Simmer Newsletter
Subscribe to the Simmer newsletter to get the latest news and content from Simo Ahava into your email inbox!
How it works
When you create a tag from the template, you have two options.
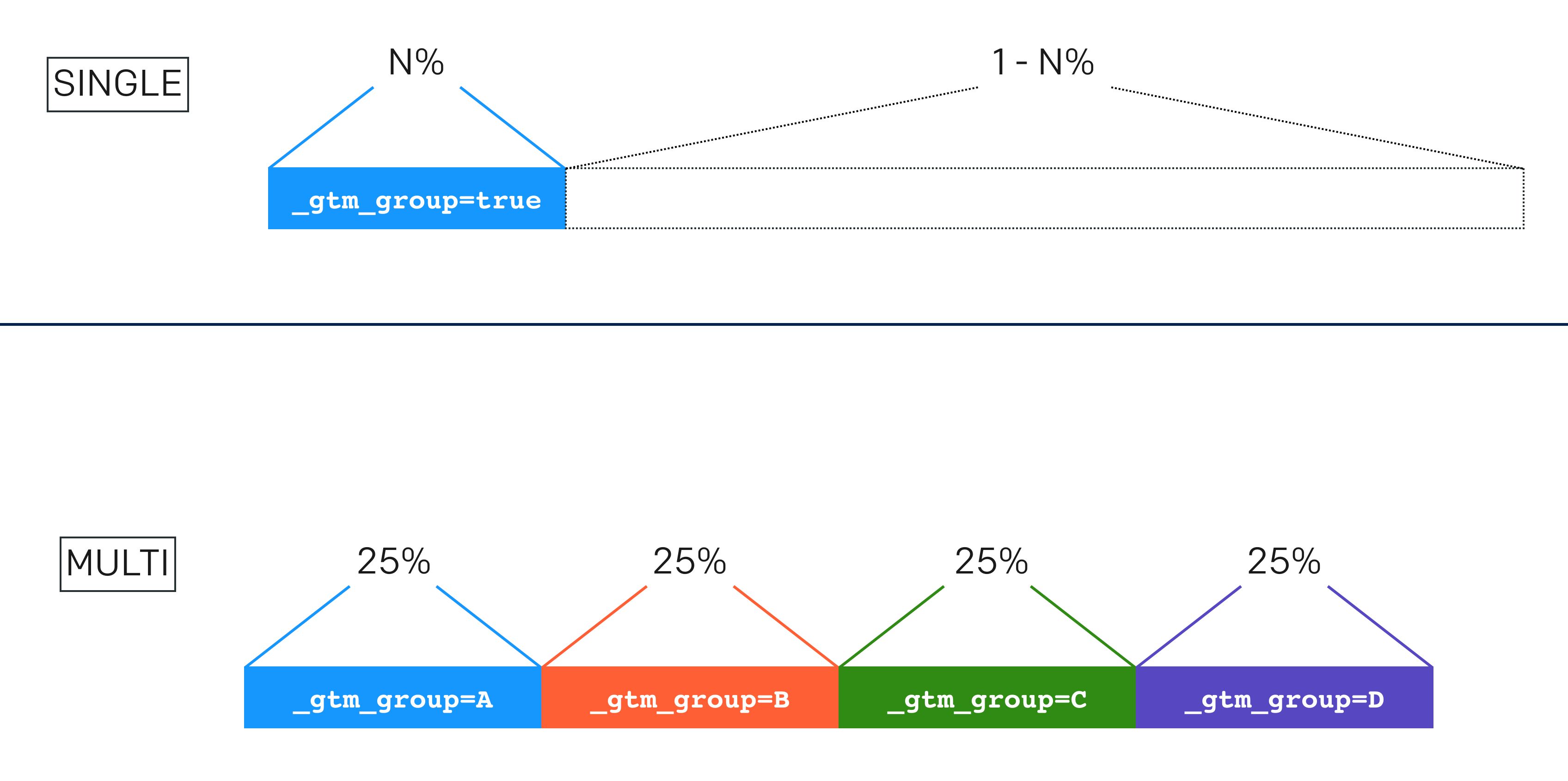
1. Single distribution
If you choose to create a single distribution, you indicate an integer percent value between 1 and 100 (inclusive). When the tag fires, a randomizer will pull a number in that range, and if the number falls into the range you gave, a cookie named _gtm_group will be written with the value "true".
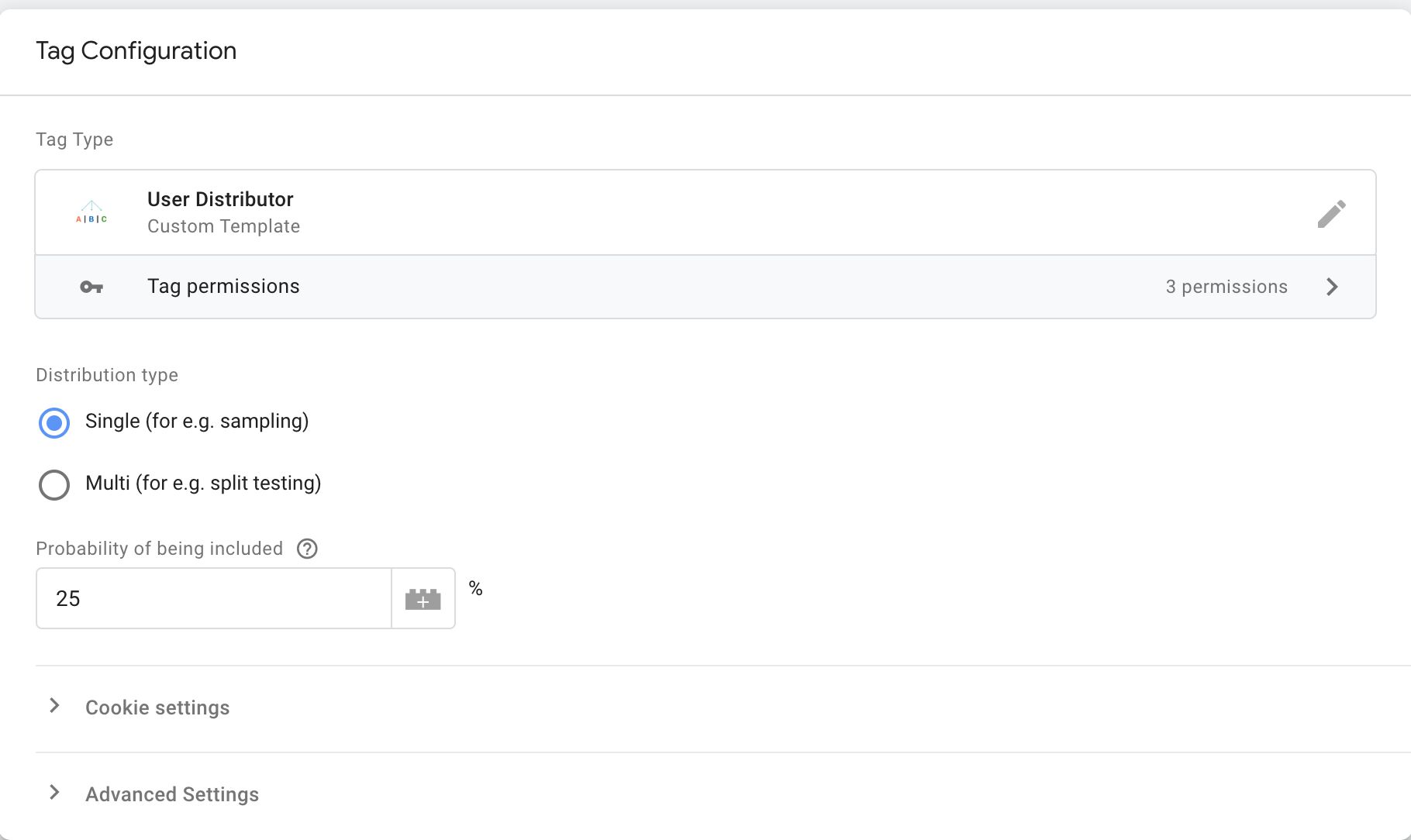
You can use this cookie to sample your visitors, for example, to keep your data collection below quotas or limitations imposed by the platforms you use.
If the number does not fall into the distribution, the cookie will be set with the value false. This is to make sure the cookie is set just once per browser.
How to use
If you set this tag to fire with the All Pages trigger, then all your users will be assigned to either the true bucket or the false bucket. Then, you can create a First Party Cookie variable for _gtm_group like this:

You can check for this cookie value in your triggers to make sure your tags only fire for those included in the group:
{{First party cookie}} equals true
Or, conversely, you can switch the value check to false to fire your tags only for those who were “sampled out”.
2. Multi distribution
The multi distribution lets you create different groups, where each group has a probability weight of including the user. You add the groups as rows in the table, where the Group value is what the _gtm_group cookie will receive as a value, and Distribution is the percentage weight (out of 100) you want to assign to the group.
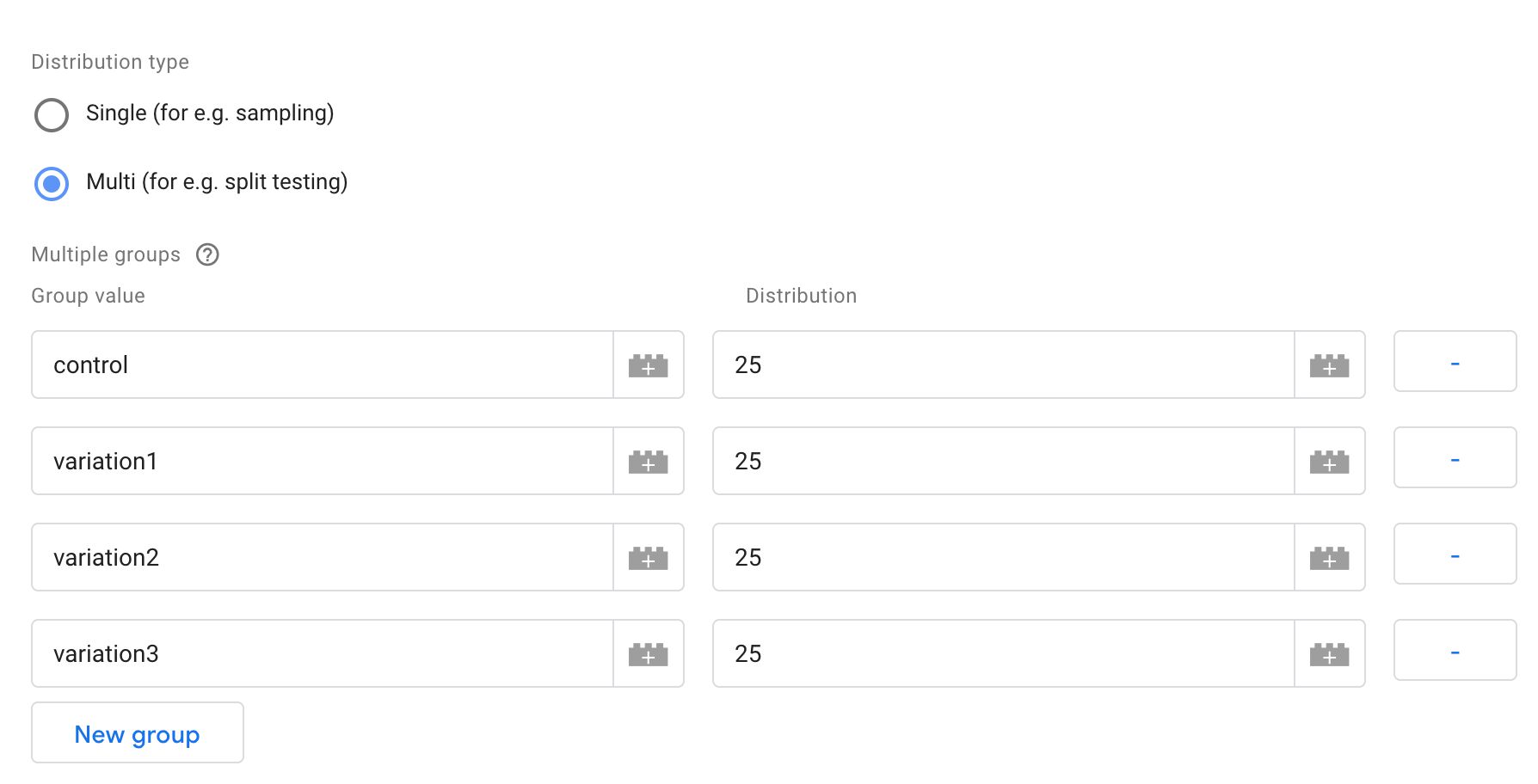
The distributions’ sum should not exceed 100. The groups are processed from top to bottom, so if the sum of distributions is over 100, the groups at the end of the table will not get their distribution probabilities met.
The sum can be under 100. It just means that there will be a probability distribution that does not set the cookie at all.
For example, let’s say you have the following items:
| Group value | Distribution |
|---|---|
| control | 10 |
| variation1 | 20 |
| variation2 | 20 |
| variation3 | 20 |
| variation4 | 20 |
When the tag fires, it randomizes an integer between 1 and 100 (inclusive). This number is then checked against the groups, starting from the top, and calculating the distribution as increments until 100 is reached.
For example, if the random number is 15., it gets included in the group variation1, because that group would include values between 11 and 30.
If the random number is 68, it gets included in the group variation3, because that group would include values between 51 and 70.
If the random number is 93, it doesn’t get included in any group and the cookie is not set.
How to use
Similar to the single distribution, you can create a First Party Cookie and use that to selectively fire your tags depending on which group the user is in. You can also use this to create distributions for A/B-testing, in case you want to control what type of content to show to users in different groups.
Cookie settings
By expanding the Cookie settings group, you can change details about the cookie that is set.
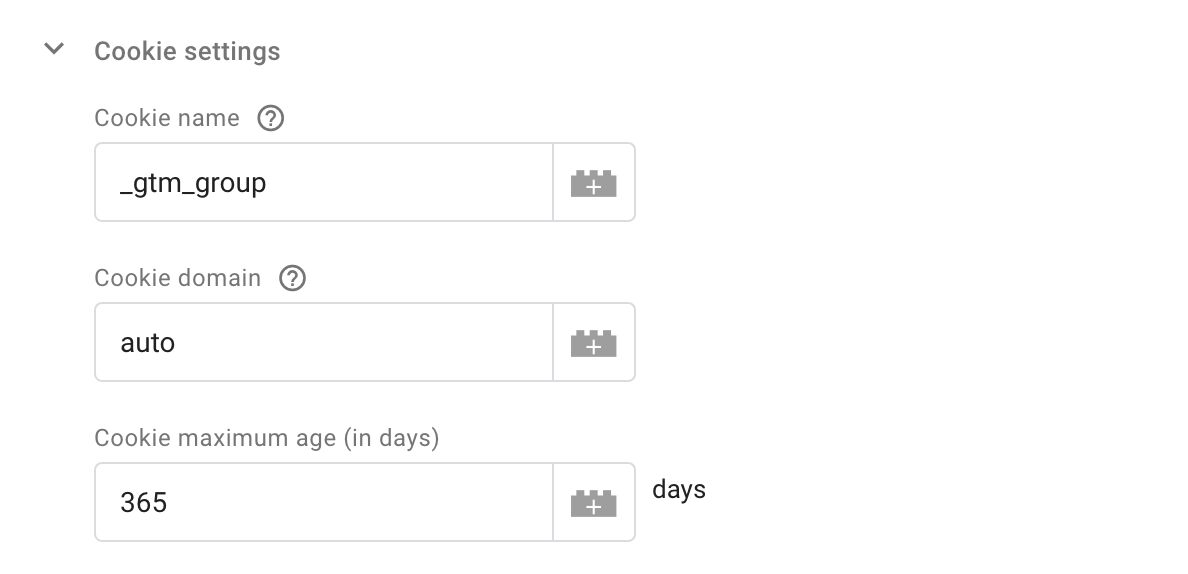
The default values are:
Cookie name: _gtm_group
Cookie domain: auto
Cookie maximum age (in days): 365
Having auto in the cookie domain fields means GTM will attempt to write the cookie on the highest domain name in the hierarchy it can. So if the user is browsing sub.domain.co.uk, GTM will write the cookie on domain.co.uk.
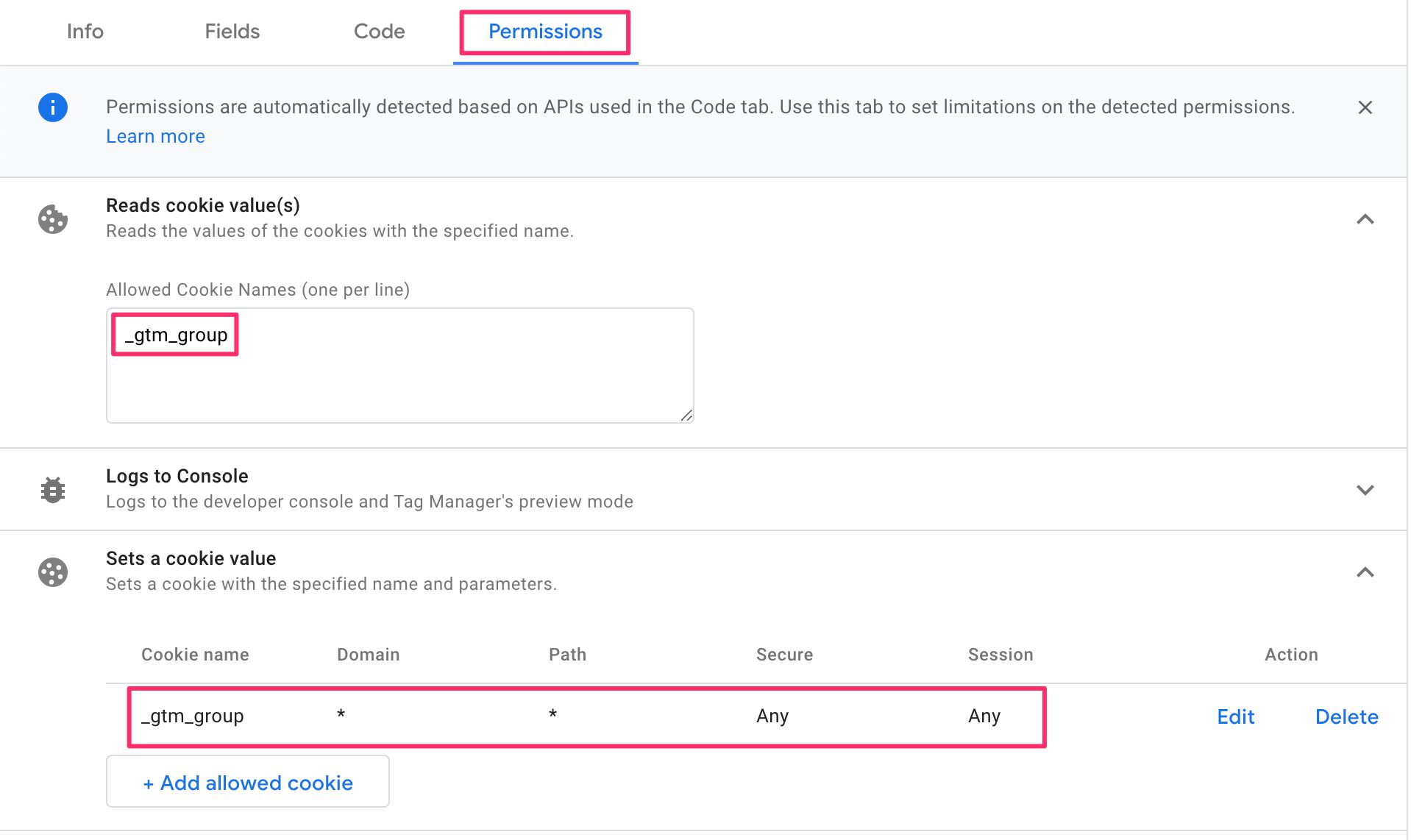
Note that if you change the cookie name, **you must edit the template permissions to allow GTM to read and write the new cookie name.
Summary
I hope you find this template useful. It’s not an exact science - the random number distribution isn’t necessarily the most robust thing in the world, and as with anything random, you need enough data to avoid outliers in the distribution.
But especially for sampling, it should be close enough for comfort.
Let me know in the comments if you have suggestions for improving the template!
