
Asynchronous Variables In Server-side Google Tag Manager
OK, that’s one unappealing title for a blog post, but rest assured that the content more than makes up for this obscurity.
Recently, my favorite toy in the world, Google Tag Manager’s server container, introduced the capability to handle asynchronous operations in variables.
This is done through a JavaScript interface known as Promise. A Promise is a way to run code in JavaScript without knowing what its eventual value will be. The “promise” part of this concept means that the code promises that it will reach a value eventually, so other code that relies on this value can execute accordingly.
In this recent update, server-side tagging APIs have been updated to handle Promises.
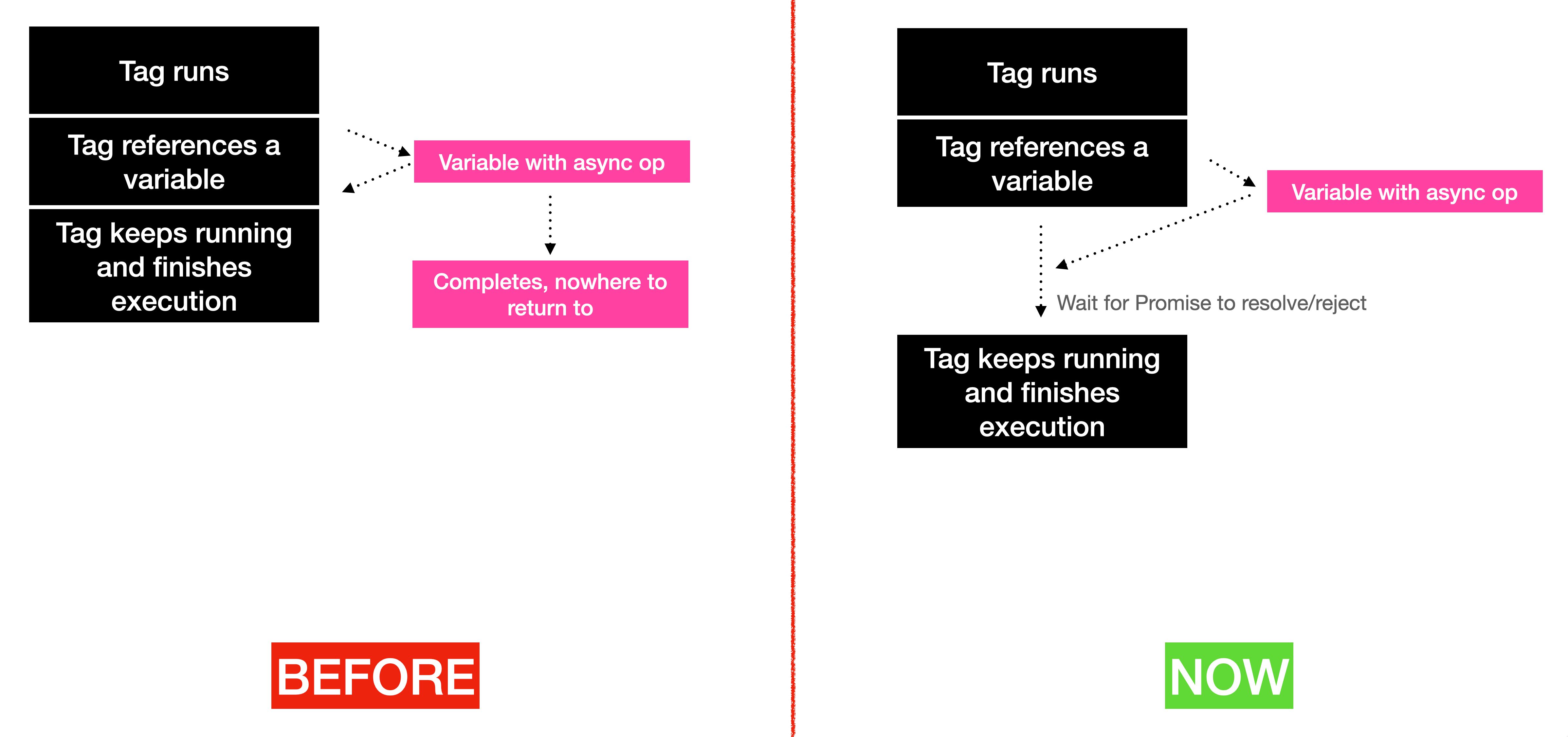
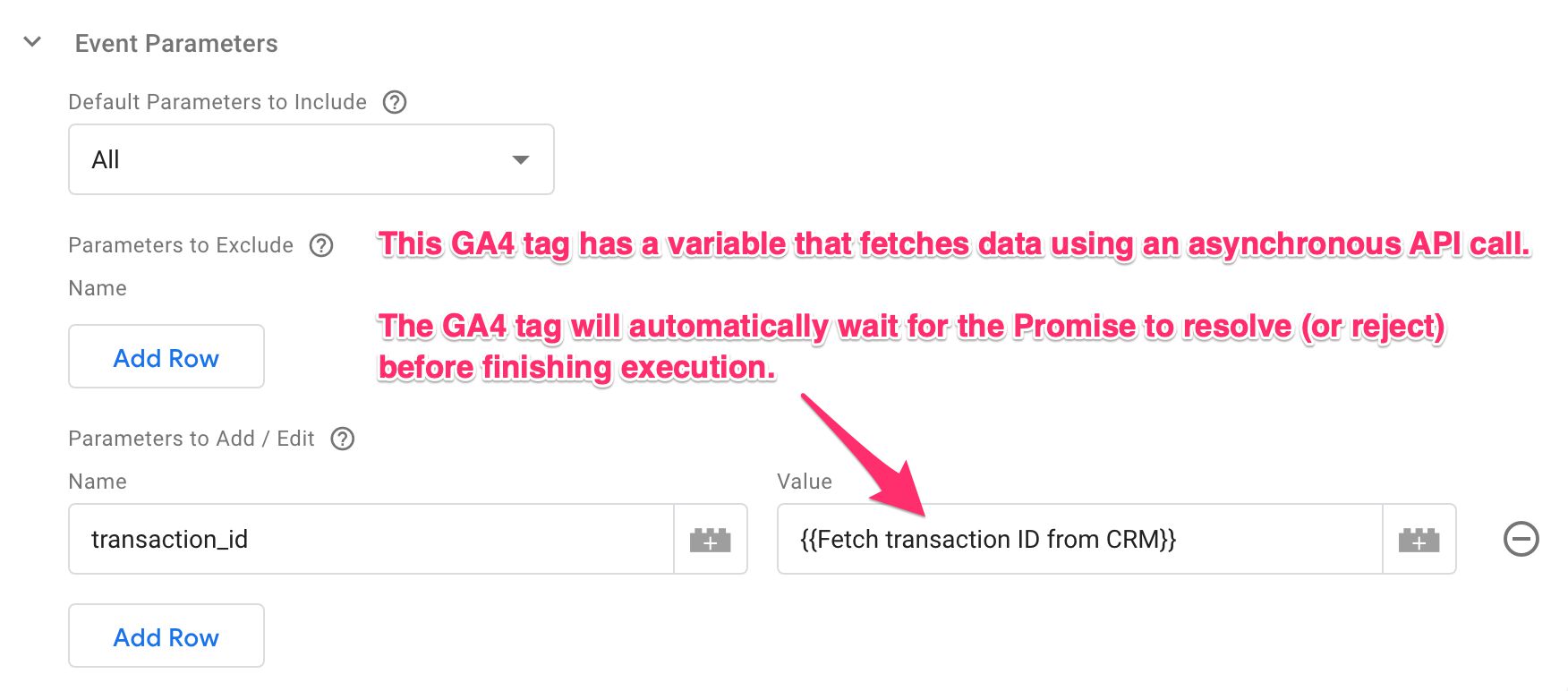
What this means in practice, is that you can attach a variable to a tag, have that variable return a Promise of completing an asynchronous operation, and the tag will automatically wait for the Promise to resolve before completing its work.
And so what, I hear you ask? You can finally enrich data streams that pass through a Server container without having to create custom Clients and Tags for it!
Just note that everything we go through in this article implicitly requires you to utilize or build custom templates, as server-side Google Tag Manager doesn’t have a “Custom JavaScript variable” option to run ad hoc code with.
Table of Contents
The Simmer Newsletter
Subscribe to the Simmer newsletter to get the latest news and content from Simo Ahava into your email inbox!
What’s changed
Previously, variables in Google Tag Manager were processed synchronously.
This meant that when the GTM runtime started parsing a variable, it executed it row by row until it reached a return statement in the execution context. That value was then returned to whatever source invoked the variable in the first place.
If the variable tried to run an asynchronous operation, meaning it did something that would eventually return a value but not when the variable was synchronously executed, the variable would just return an undefined value because GTM wouldn’t wait around for the variable to complete.
With this change, variables can now return a Promise, which the runtime code then waits to resolve before proceeding. In other words, the variable doesn’t have to resolve to a value immediately – it can return a solemn promise that it will eventually reach a value (of course within a given timeout).
And why is this a big deal? Because until now, if you wanted to have your tags and Clients wait for some asynchronous operation, you had to embed these asynchronous calls into the tag / Client code itself.
Now all you have to do is make sure the variable returns a Promise, and whatever called the variable will dutifully wait for that Promise to be either resolved or rejected.
How to work with Promises
Luckily, you don’t have to worry about the Promise interface itself.
Although you can use the new Promise API to create custom Promises, and the more hard-core programmers out there can certainly make use of Promise.all to chain together multiple Promises, many built-in server-side tagging APIs have been automatically updated to utilize the Promise interface.
Here’s an example of using Promise.all in a variable template:
// Run multiple API calls and return a single Promise that's resolved when all the API calls have resolved
const Promise = require('Promise');
const sendHttpRequest = require('sendHttpRequest');
return Promise.all([
sendHttpRequest(FIRST_API_URL, FIRST_API_OPTIONS),
sendHttpRequest(SECOND_API_URL, SECOND_API_OPTIONS)
]).then(results => {
// results will equal [{statusCode: 200, headers: {}, body: ...}, {statusCode: 200, headers: {}, body: ...}];
if (results.filter(result => result.statusCode === 200).length === 2) {
return "Both API calls executed successfully!";
} else {
return "Oops, something went wrong!";
}
});How existing APIs have changed
The BigQuery, sendHttpGet, and sendHttpRequest APIs (and the new Firestore API!) are likely to be the ones you’ll be using most in this new context. They let you run asynchronous HTTP requests to endpoints (such as your enrichment API), and the response can be then used to enrich your tags’ and Clients’ data streams.
To work with them, you just need to utilize the new Promise-friendly syntax. If you’re running this in a variable, remember that the variable needs to return the Promise. The actual return value will be set to what the Promise instance methods ultimately return.
Promises timeout after 5 seconds if neither resolved nor rejected. If the API has its own timeout set (such as the
sendHttpRequest), then that will be honored instead.
Here’s an example of how you would approach a simple GET request. This API polls the Circle.so public API and returns the number of members in the community the authentication token is created for.
const sendHttpRequest = require('sendHttpRequest');
const JSON = require('JSON');
const AUTH_TOKEN = 'XXXXXXXXXXXXX';
const API_URL = 'https://app.circle.so/api/v1/community_members';
const OPTIONS = {
headers: {Authorization: 'Token ' + AUTH_TOKEN},
method: 'GET',
timeout: 2000
};
// Return the Promise
return sendHttpRequest(API_URL, OPTIONS).then(success_result => {
const members = JSON.parse(success_result.body);
// When the Promise resolves (successfully), the length of the array in the response body is returned
return members.length;
});Promises have three methods:
.then()takes two functions as parameters (above I only use the first one, though). The first is for what happens when the Promise is resolved successfully, and the second is for what happens when the Promise is rejected..catch()takes a single function as a parameter, and it’s executed if the Promise is rejected. This is a handy way to isolate code only for error resolution..finally()takes a single function as a parameter, and it’s always executed whether the Promise was resolved or rejected.
So in the example above, I’m only focused on successful resolution, but I could just as well add a .catch() step there to handle issues. However, as this is a simple GET request, I don’t see any reason to specifically treat error cases, so I’m OK with the variable returning undefined in case it runs into an error.
Caching
To prevent the same API call from being made over and over again, there’s a caching mechanism in place. The cache is scoped to the incoming request, so once a new request comes in to the Server container, the cache is reset.
The cache only works if the response is cacheable. In other words, the cache isn’t forced on resources that should not be cached.
If you want to add additional caching with more control, you can utilize the templateDataStorage API for this.
Remember that all outgoing requests are considered network egress traffic by the cloud service, and you will need to pay for that network usage. Thus caching is a very important thing to have in place – one way or another.
One thing that I’d love to see is the option to override the Event Data object produced by the Client with these asynchronous variables. That way you could add the enrichment variables to the Event Data object itself, and they would be available to all the tags, triggers, and variables that utilize this object.
This would sort out the caching problem completely, too, because the variable would run just once: when resolved in the Event Data object.
Summary
Although this has been a very technical overview, I hope you see the promise (pun intended) of this update to server-side Google Tag Manager.
Data stream enrichment has been one of the things I’ve been harping about as a unique selling point of a server-side tag management solution, so I’m really glad we finally have a handy way of doing so. It’s been two years since server-side tagging in GTM was publicly announced, after all!
Now, the ball is in the community’s court.
Get creative with those variable templates!
I want to see the Community Gallery stuffed with utility variables for polling different APIs, handling HTTP communications, and running asynchronous operations to enrich those Clients and tags that might benefit from them.
What do you think about this release? Can you think of use cases where these new Promises could be particularly helpful?
