From Project To Process
This year I had the opportunity to present at eMetrics London and Berlin on a topic that is very close to my heart. I’m psychotically neurotic about data quality. I’ve written about it many times before, and it’s pretty much why I want to keep on blogging and writing about analytics and tag management customizations. At eMetrics, I stepped out of my comfort zone of development and implementation, and chose to talk about organization practices.

For the past number of years, I’ve had the fortune of working with some amazing clients and colleagues, helping entire organizations understand the concept of meaningful data and how data is always an investment. In this article, I want to pull some of these threads together, and explain how I approach data quality and the optimization thereof within an organization.
XThe Simmer Newsletter
Subscribe to the Simmer newsletter to get the latest news and content from Simo Ahava into your email inbox!
Disclaimer
As always, I do not want to preach, nor do I have any authority to tell others how to conduct their business. Quoting my good friend Craig Sullivan, experts and best practices are “rather rare and mystical beasts”.
All we can rely on are the experiences of people we trust.
If we find these experiences useful, and we can trust that the person who shared them knows what they’re talking about, we can see if these experiences could be adopted by whatever environment or context we are working in. This, I think, is lost to many who’ve succumbed to the ease of finding answers instead of methods. Too often, people ask for Please do this for me instead of Please show me how it works.
The way I approach learning new things is to find experiences with which I can relate, after which I dissect these experiences, trying to recreate them in a way that is most beneficial to me and my goals.
In this article, I will be sharing my experiences of working in and with various types of organizations. If some of these thoughts resonate with you, then I’m glad, and I look forward to hearing what you think about what I’ve written. If this sounds alien to you, then I’m equally glad, and I look forward to explaining myself further in the comments.
1. Don’t screw up data collection
Surprise, surprise, I’m all about data collection. I don’t hesitate to say that it’s the most crucial part of the web analytics process. But what about analysis, insights, visualization, segmenting? I hear you say. Yeah, those are really important as well, but if you screw up data collection, you screw up all the subsequent stages as well.
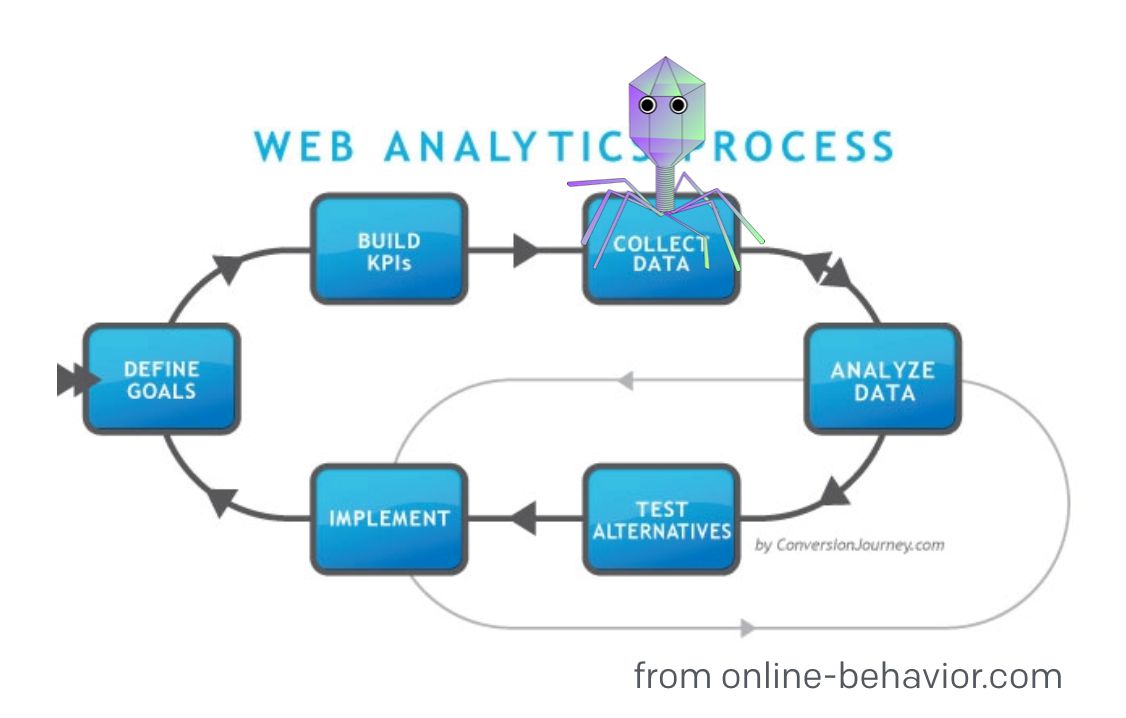
That image above, lovingly adopted from online-behavior.com (my favorite analytics blog), illustrates this nicely. I used my Photoshop skillz to copy-paste the cute little diamond bug on top of the “Collect Data” node. This represents a virus that has infected data collection. It means you’ve either failed or forgotten to measure something on the site. As you might guess, it means that this data is either not available or is corrupt.
A typical example is in Ecommerce tracking. Ecommerce comprises such a huge number of variables that successful comparison across date ranges would require that these variables be encoded consistently across different points in time. How often does that happen? I’m willing to say rarely, and the likelihood decreases with time. However, still we see people comparing Revenue from last quarter (which included shipping and tax) with Revenue from a year ago (which did not include shipping and tax). The very fact that they have different aggregation methods means that they can’t be compared unless you know how these methods differ. Unfortunately, this information is often misplaced when teams and organizations change.
In other words, data collection is an investment. It requires labor, love, and a crystal ball. It’s one of the most difficult things to get right, and requires a lot of experience. But there’s nothing, nothing as frustrating as data that’s missing or incorrectly collected.
2. Analytics as a PROJECT is the root of all evil
Here we go: diving into the controversial end of the pool. Let me juice it up with another claim.
Data quality is destroyed by ineffectiveness and non-involvement.
Let’s see if we agree on this. Are you, or have you been, affected by the following phenomena in your organization?
Monthly reports, which lack relevance, are rife with generic suggestions that lack research in the context of your business, reiteration of previous month’s points, even if there are solid reasons why they weren’t addressed
Ridiculously ugly and ineffective JavaScript hacks for measurement points, which should be tackled in the Data Layer
Clueless managers who want you to fix metrics rather than the underlying reasons that output the data into those metrics (“Fix our Bounce Rate, please!”)
Analytics features are deprioritized, and deployed extremely infrequently
These are all symptoms of data being treated as a project outcome! They smack of non-involvement. They are deliverables and off-shoots of mail-order projects, where an entire analytics process is treated as something that can be time-boxed, outsourced, and ignored.
In the agency world, these assignments were quite typical. It’s not because the agencies are lazy (well, sometimes it’s that too), but it’s because organizations have not matured enough to turn analytics into a business-driver, and treat it as a diagnostics tool instead.
What I’ve learned is that the only way to make analytics truly work in an organization is to implement it as a process. As consultants, we can be “purchased” to help get things moving. This might mean an implementation project, or a consultancy project, but the key deliverable of these projects is a shift in the momentum of the organization that we are trying to help. If the organization chooses to externalize analytics to an “extra pair of hands”, which happens ever so often, they will lack the incentive to actually integrate an understanding and respect of data into their processes.
3. Tag management solutions help us fight Conway’s law
One of the reasons analytics is so difficult to integrate into organizations is because it’s cross-disciplinary. I wrote about this in a recent article in my company’s blog (10 Truths About Data):
Data is the lifeblood of the organization. It flows through all departments, across job titles, permeating the very fabric of the organization, reinforcing its foundations for growth. It cannot and should not be contained in one vector (a dedicated analyst) alone.
Now, try to think of anything in a modern organization that works like that. It’s difficult, right? A typical organization is riddled with departments and silos, and there’s just so much friction in the seams.
In 1968, Melvin Conway said something pretty insightful, which was then coined into a law bearing his name. The law is approximated as (quoting Wikipedia):
organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations
In other words, if the departments within your organization (e.g. IT and marketing) are unable to communicate with each other, any systems they manage or want to create (e.g. the CMS and an analytics platform) will be unable to function together as well.
This is one of the reasons we resort to projects so eagerly. By requesting a project, we are allocating our department’s budget to said project, and we’ll receive something that’s optimized for our department, and our department alone. For example, the marketing department might want to implement Google Analytics on some new landing pages, and they request the help of an agency to write the implementation plan. The result is an implementation plan that only tackles the problems the marketing department outlined, instead of treating data collection as something owned by the entire organization.
The agency might also utter the most ridiculous words in the history of language:
“We recommend you install Google Tag Manager, because then we won’t need IT anymore to implement analytics measurement.”
I’m not a violent man, but when I hear or see that argument it makes my blood boil. I feel very strongly about this, and for a good reason. Nothing is as detrimental to an organization as an outside influence (e.g. agency) that communicates only with a single point of contact (e.g. marketing), but inadvertently gets mixed up in something that spans the entire organization (the IT infrastructure).
Friends, compatriots, fellow analytics aficionados: data and analytics belong to the entire organization, not just a subset thereof. It’s unnerving, and quite honestly impossible, to try to implement something as significant as a bloody JavaScript injector (which a tag management solution often is) without involving the developers or IT!
In fact, I want to make the following bold claim:
A tag management solution empowers DEVELOPERS more than others.
We implement a tag management solution because we want to harness a very developer-centric tool to facilitate communication within our organization. This necessarily involves multiple disciplines in the decision-making process. If you entrust a TMS solely in the hands of a department or individual that already has prejudices against working with developers, it will only inflame this relationship further.
The way I see it, an optimal implementation of a tag management solution is perfect for mitigating the effects of Conway’s law. Similarly, a cooperative IT or developer process is paramount in an optimal implementation of a tag management solution.
4. Data Layer is the universal translator
You see, a tag management solution is built on top of a Data Layer. Typically, we have a number of definitions for a Data Layer, but here are the three I most often fall back to:
A set of business requirements, encoded as key-value pairs against each hit, visit, and visitor that your digital property might collect
A uniformly encoded, global data structure that collects and distributes data on the digital property
An internal data model in the tag management solution with which you communicate through the global data structure
OK, let’s try again. That was confusing.
The purpose of a Data Layer is to provide a **bilateral** layer on the digital asset, which **decouples**, **normalizes**, and **uniformly encodes** semantic information passed through and stored within.
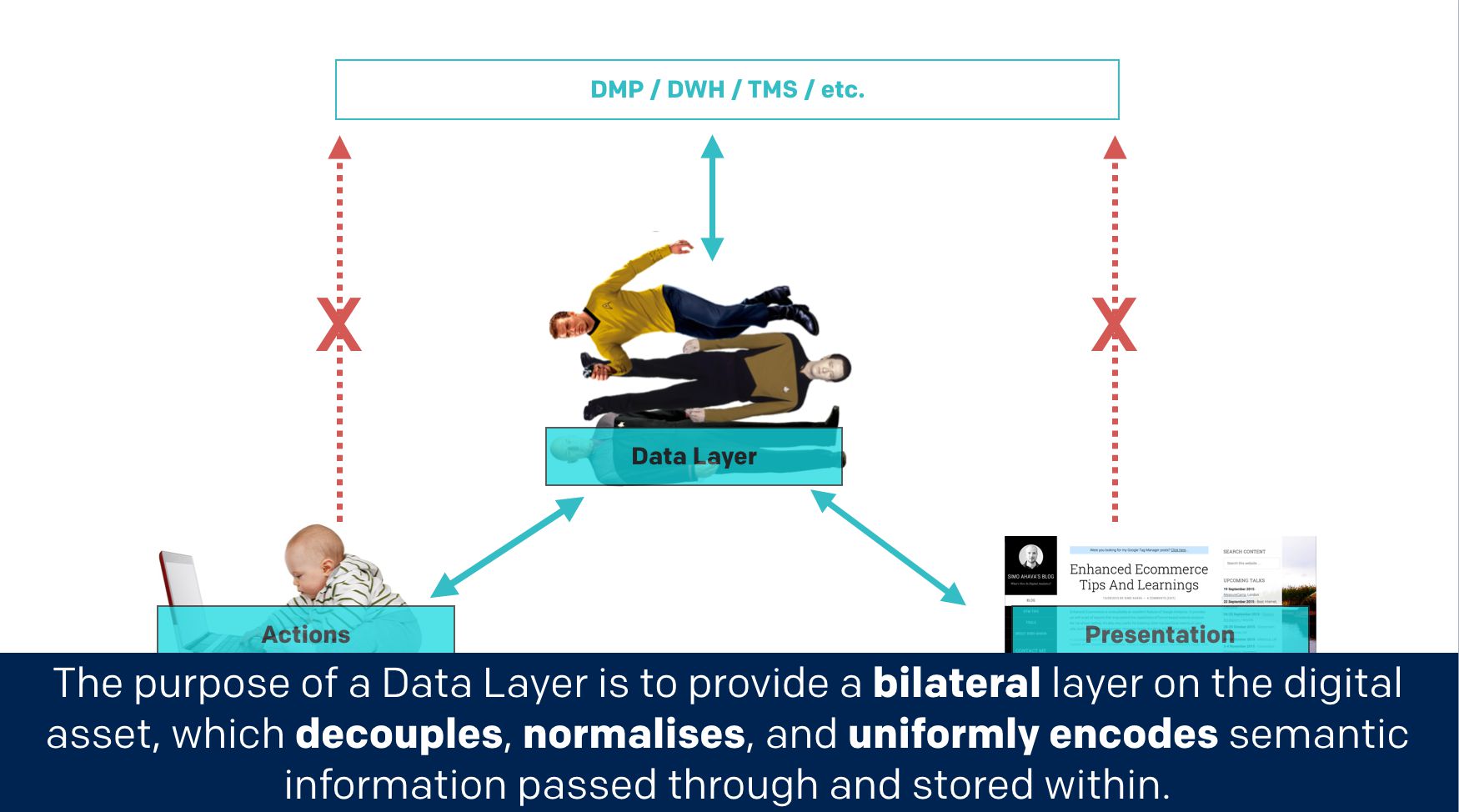
Hmm, I’m not sure that made any sense either.
Look, the Data Layer is a translator. It forces you and your buddies in IT to communicate using a common syntax. It’s a joint venture, where people and systems communicate across silos. You can keep on hating the gremlins in the IT lair if you want, but you’d better respect and love the Data Layer. If you don’t get this right, then you can just chuck the TMS out of the window, as it won’t be worth the migration.
Perhaps unsurprisingly, I’ve written about the Data Layer before, and the more I work with organizations, the more I place my faith in its transformational power.
When crafting an implementation or measurement plan, involve all the relevant departments and individuals in the process, and speak only Datalayerian. Instead of writing vague descriptions of what you might want to measure, write down key-value-pairs. Start and end with the Data Layer, in all parts of the implementation and data collection process. Let she or he who knows the constraints of this structure best lead the discussion. Translate all requirements you hear into variables and values, associated with their respective measurement points.
5. Empower and facilitate the developers
My past year at Reaktor has only strengthened something I already knew: agility is extremely helpful in the proper implementation of an analytics process.
It’s not easy in a world still dominated by the pitfalls of the waterfall, where projects comprised distinctive stages, each with entry and exit conditions.
The handovers between the discrete stages of the waterfall are where data is most often corrupted! When a deliverable is passed from one stage to another, it’s always a release rather than a continuum. Whoever passed the information is absolved of responsibility outside that of the deliverable, and whoever received the setup is forced to survive the possible conflicts, quality issues, and misgivings of the previous stages.
The void between the project milestones is where good data turns bad.
Instead, what if we treat the process not as a collection of milestones but rather something that’s on-going and part of everything we do in our front-end or app development?
The first thing I want to implement in an analytics process is a proper consideration of measurement when developing features.

Since the agile process is, by nature, quite chaotic, we need something to facilitate quality assurance. Often, this comes in the shape of a Definition of Done. It’s a set of conditions that determine what is considered a success in the development process.
If we add analytics and measurement requirements into the Definition of Done, we are actually mitigating data quality issues even before they crop up. By making sure that developers consider measurement when developing or updating features, we are cultivating a perfect breeding ground for successful data collection.
This requires, of course, that the developers are aware of what measurement entails. I could refer you to read the previous chapters again, but I can just reiterate myself here:
A tag management solution empowers DEVELOPERS more than others.
Whenever I start working with a client, I educate the developers first. This might include:
Helping them design modules and interfaces for communicating with the Data Layer
Getting them up-to-speed in front-end development and the requirements that tag management solutions place on the document object model
Inspire them to create a sandbox for tag management solution testing (this WASP playground is pretty much what I have in mind)
Only hire to educate, not to delegate
Oh, that last point is so important. I respect the naïveté and hypocrisy (as I’m also a consultant) of the statement, but I truly believe in it.
A good consultant should work in a manner that inevitably makes them redundant.
Take that statement with a grain of salt. What I mean is that if you hire consultants for outsourcing tasks that should be handled within your organization, you not only create an unfavorable dependency, but you also lose the opportunity to improve your own processes.
Data collection and analytics are prime examples of this. I have most success when working in the client’s premises, being extremely transparent about everything I do, and working together with their key players so that they can eventually do everything I’ve done themselves. This builds trust and helps the consultant find new areas to improve and focus on, rather than things that are trivial to the consultant but super important to the client.
Summary
This text is a summary of what I’ve been talking about this past year in conferences. I’m crazy passionate about data quality, data collection, and facilitating growth in organizations.
I believe in this stuff with every fibre of my being.
I believe that successful projects morph into processes. They rejuvenate organizations, and build trust across silos that are engaged in ridiculous trench warfare, propagated by inflexibility and complicated hierarchies.
I believe that an empowered developer is at the heart of a successful analytics project. However, the entire team works together to build bridges from business requirements, through the Data Layer, all the way to reports.
I also believe that data is difficult. I’ll end this article with another one of my “10 Truths About Data”:
Data is difficult. It has to be. There are no short-cuts, no omniscient tools, no out-of-the-box solutions that give you perpetual satisfaction. The entire life cycle of a single data point, from collection to reports, requires knowledge and expertise to manage. Turning arbitrary numbers into actionable insights is not, and never will be, a walk in the park.
Do you agree?
