Ever since the Lookup Table variable was introduced in Google Tag Manager, users have been craving for more. The Lookup Table does exactly what it promises: lookups. These are exact match operations, which are extremely inexpensive to perform, because they can only have a binary result: either the match exists in the data store being queried or it doesn’t. This performance stays constant even if the data store being queried increases in size. However, exact match has one significant problem: it’s exact match. Thus even though the Lookup Table variable is extremely useful, it’s missing the flexibility of, I don’t know, say, regular expressions. You will be pleased to hear, then, that Google Tag Manager has released a new variable type: the RegEx Table!
{kind=link}
First of all, if you are unfamiliar with regular expressions, here are some great resources:
Needless to say, RegEx is a powerful pattern-matching syntax to learn, and can help you enormously in keeping your Google Tag Manager container lean and mean.
The Simmer Newsletter
Follow this link to subscribe to the Simmer Newsletter! Stay up-to-date with the latest content from Simo Ahava and the Simmer online course platform.
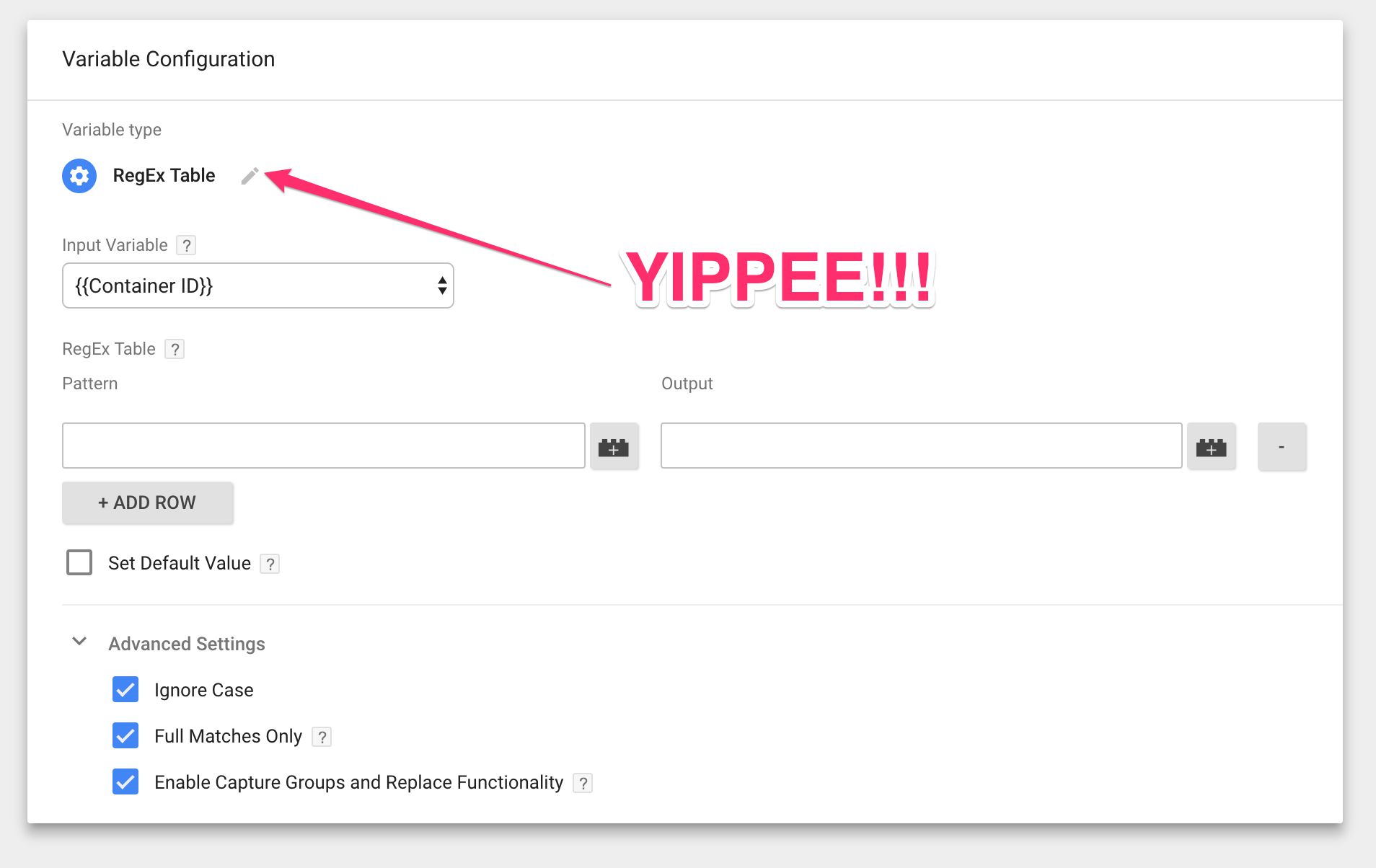
The RegEx Table variable
You’ll find the RegEx Table variable in the list of variable types you can create as a User-defined variable. Once you choose this variable type, you’ll see the following configuration:
{kind=link}
There are many similarities with the Lookup Table variable, for good reason, but there’s also a bunch of settings that turn this new variable into a formidable force in its own right.
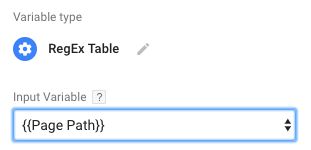
1. Input variable
The Input variable shares its functionality with the Lookup Table. The input variable is what you’ll be making your pattern checks against. For example, if you want to use the RegEx table to look for patterns in the current page path, you’d choose the {{Page Path}} variable as the input.
{kind=link}
The input variable is evaluated row-by-row, from top-to-bottom, against each pattern. When a pattern matches, the respective output is returned and processing of the table stops.
2. RegEx Table
Next, you have the table itself. In the table, you add rows, where each row represents a pattern you want to match in the input, and an output returned by the variable in case the pattern matches.
The pattern is always interpreted as a regular expression. All the following patterns are valid examples:
simoahava.com- will match “simoahava <+ any character +> com”simoahava\.com- will match “simoahava.com”.^simoahava\.com$- will match exactly “simoahava.com” (won’t allow leading or trailing characters).(simoahava)\.com- will match “simoahava.com” and create a group (see below) of “simoahava”.
A pattern like [simoahava\.com is not a valid regular expression, because “[” is a reserved character, and it is being incorrectly used in this pattern. Google Tag Manager will not warn you of errors in the regular expression, but you’ll know something is wrong if the Preview mode output for the variable is boolean false. Conversely, if no match is made or there is no output for a matched pattern, the variable will return undefined.
The output is what the variable returns when a row is matched against the input. The return type is a string, unless you add another variable into the output. This is a great way to chain RegEx Table variables, just as you could chain Lookup Table variables.
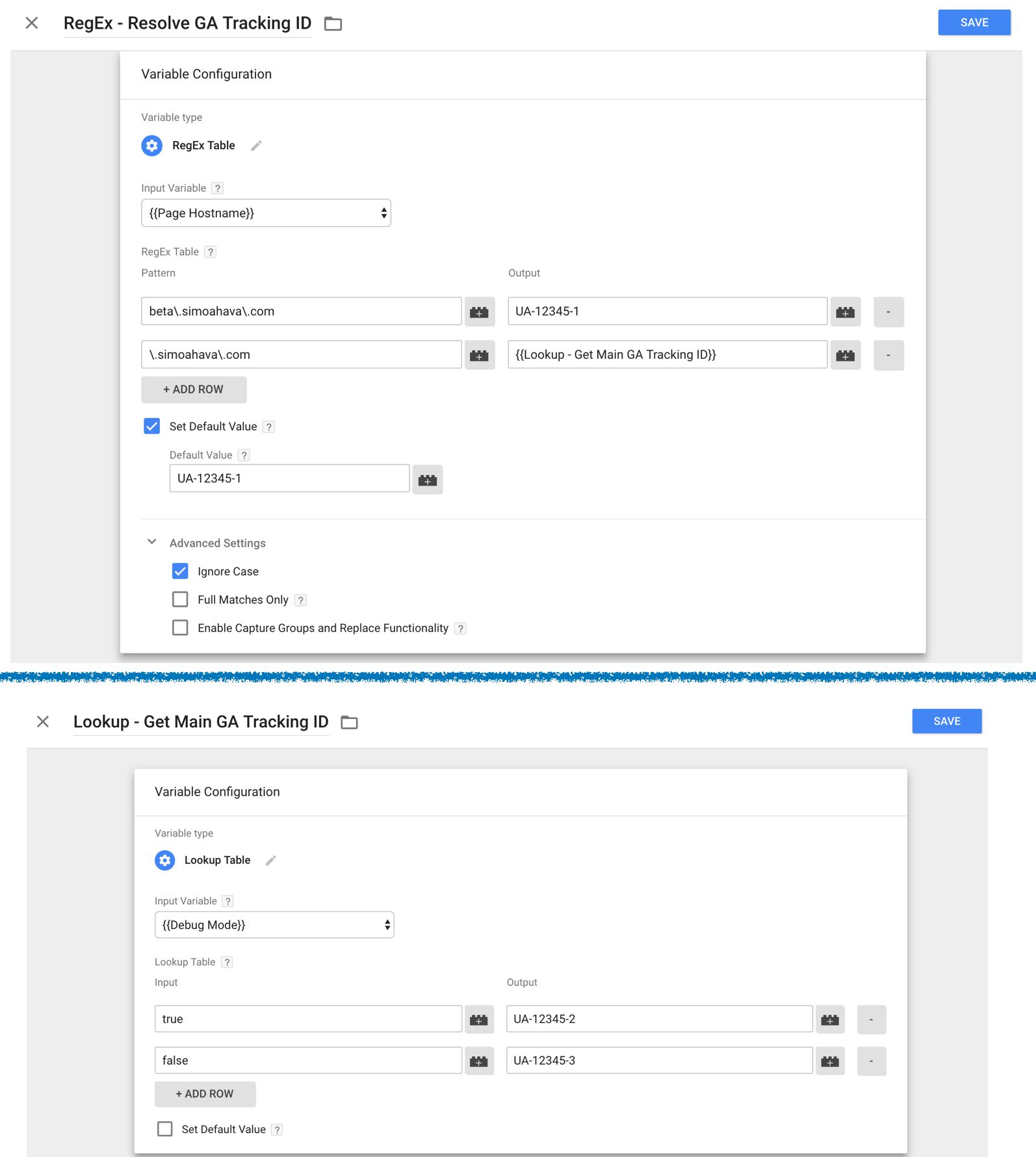
For example, here’s a simple chain of a RegEx Table and a Lookup Table:
{kind=link}
And here’s how to unravel the process:
If the page hostname matches the pattern
beta\.simoahava\.com, then return “UA-12345-1”.If the page hostname doesn’t match either
beta\.simoahava\.comor\.simoahava\.com, also return “UA-12345-1” (Default Value of the RegEx table).If the page hostname matches
\.simoahava\.comand the user is in Debug Mode, return “UA-12345-2”.If the page hostname matches
\.simoahava\.comand the user is not in Debug Mode, return “UA-12345-3”.
As you can see, the RegEx Table returns the first match that is made. Thus even though beta\.simoahava\.com and \.simoahava\.com overlap for any hostname that contains the string “beta.simoahava.com”, the RegEx table returns “UA-12345-1”, because that is the first match that the variable makes.
3. Set Default Value
As with Lookup Tables, you can set a Default Value that is always returned in case no match is made. Just like pattern outputs, this can be another Google Tag Manager variable.
4. Ignore Case
If you check Ignore Case, patterns are matched regardless of case. So a pattern with WwW\.SiMOAHava\.com will match against the domain of my site, as long as Ignore Case is checked.
Ignore Case is checked by default.
5. Full Matches Only
If you check Full Matches Only, then all patterns must match the entire input. This is the equivalent of wrapping each individual pattern with ^...$.
For example, if you have Full Matches Only checked, and you have a pattern of www\.simoahava\.com, then the input variable must return exactly www.simoahava.com, without any other characters. If you’d have the setting unchecked, then www\.simoahava\.com would also match any of the following:
greatest.website.ever.is.www.simoahava.comaawwwwww.simoahava.comvisit.www.simoahava.com.please
And so forth.
Full Matches Only is checked by default.
6. Enable Capture Groups and Replace Functionality
This is interesting! In addition to matching the input against a pattern and returning a corresponding output, you can actually use parts of the matched pattern within the returned output. This is achieved with capturing groups and the dollar symbol syntax.
A group (capturing and non-capturing) in RegEx is a pattern that you define with parentheses. Most groups can then be captured using the dollar symbol syntax when using the String.replace() method or, consequently, the Enable Capture Groups and Replace Functionality feature of GTM’s RegEx table. Here are the options for the dollar symbol syntax:
$$inserts a ‘$’.$&inserts the matched pattern.$`inserts whatever precedes the matched pattern in the string.$'inserts whatever follows the matched pattern in the string.$ninserts the _n_th capturing group.
These all have their uses, but the last one, $n should prove to be the most useful. You can use it to normalize patterns across a range of values. For example, let’s say you have a variable which stores the user’s phone number in the following formats:
358101001000
0101001000
010-1001000
010 100 1000
+358101001000
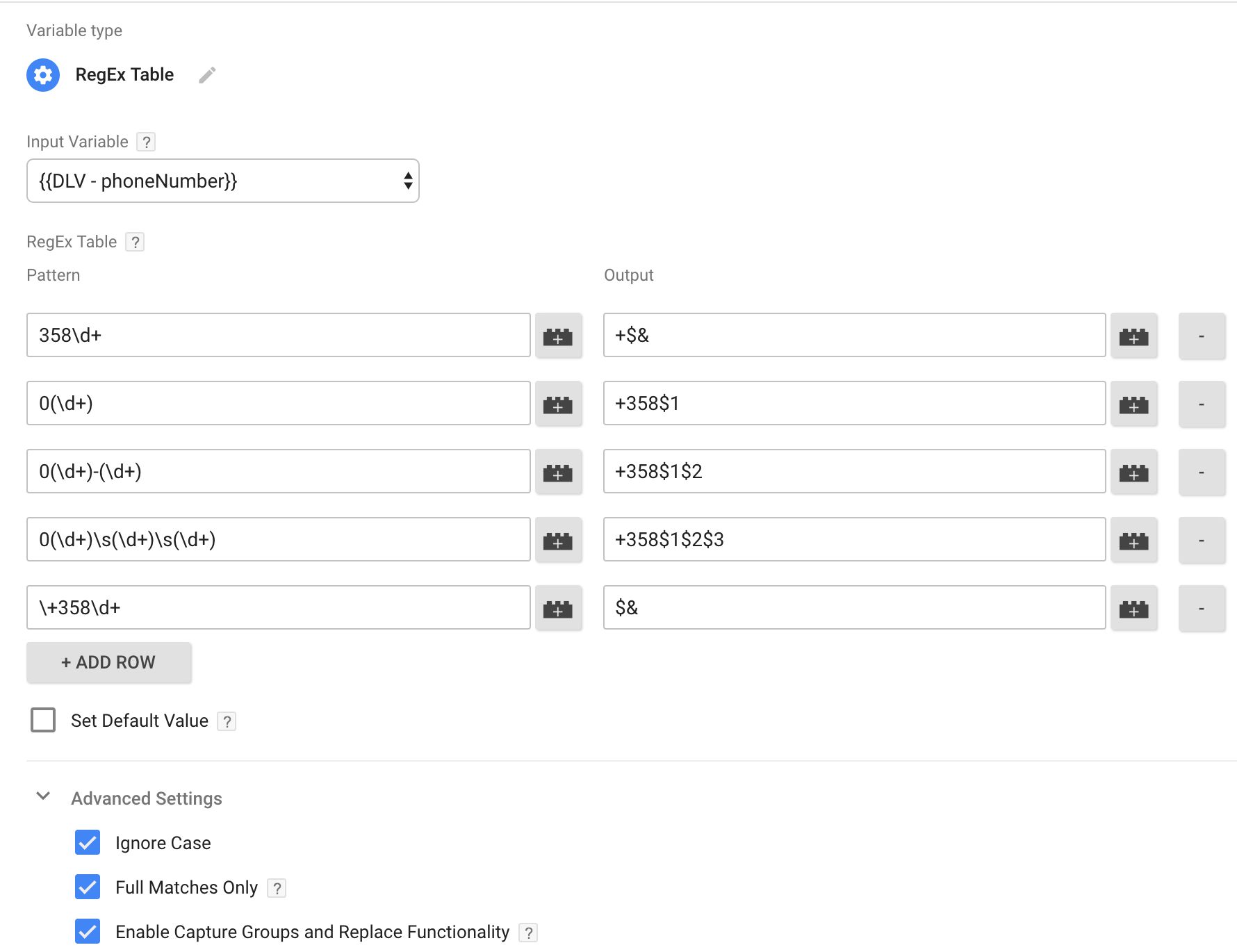
You want to normalize all of these to the last format (+358101001000) whenever the phone number variable is used. This is how you’d configure the RegEx table:
{kind=link}
The first pattern looks for strings that start with ‘358’ followed by any numbers. This pattern is simply replaced with the plus symbol followed by the pattern itself.
The second pattern looks for a string of numbers preceded by a ‘0’. The output is ‘+358’ and the string of numbers, omitting the leading ‘0’.
The third pattern looks for a string of numbers preceded by a ‘0’, then a hyphen, and then a string of numbers again. The output is ‘+358’ and then the two strings of numbers, omitting the leading ‘0’ and the hyphen.
The fourth pattern looks for a string of numbers preceded by a ‘0’, then a space, then another string of numbers, a space, and finally one more group of numbers. The output is ‘+358’ and the three groups of numbers, omitting the leading ‘0’ and the spaces.
The final pattern checks if the phone number is already well-formed, returning the pattern itself if this is the case.
Using the RegEx Table like this, we can create simple string transformations which help normalize and clean up data across a variety of formats. As you can see, Full Matches Only is checked in this example. That means we don’t have to worry about anything that happens outside the matched pattern, since only full matches to the pattern are transformed.
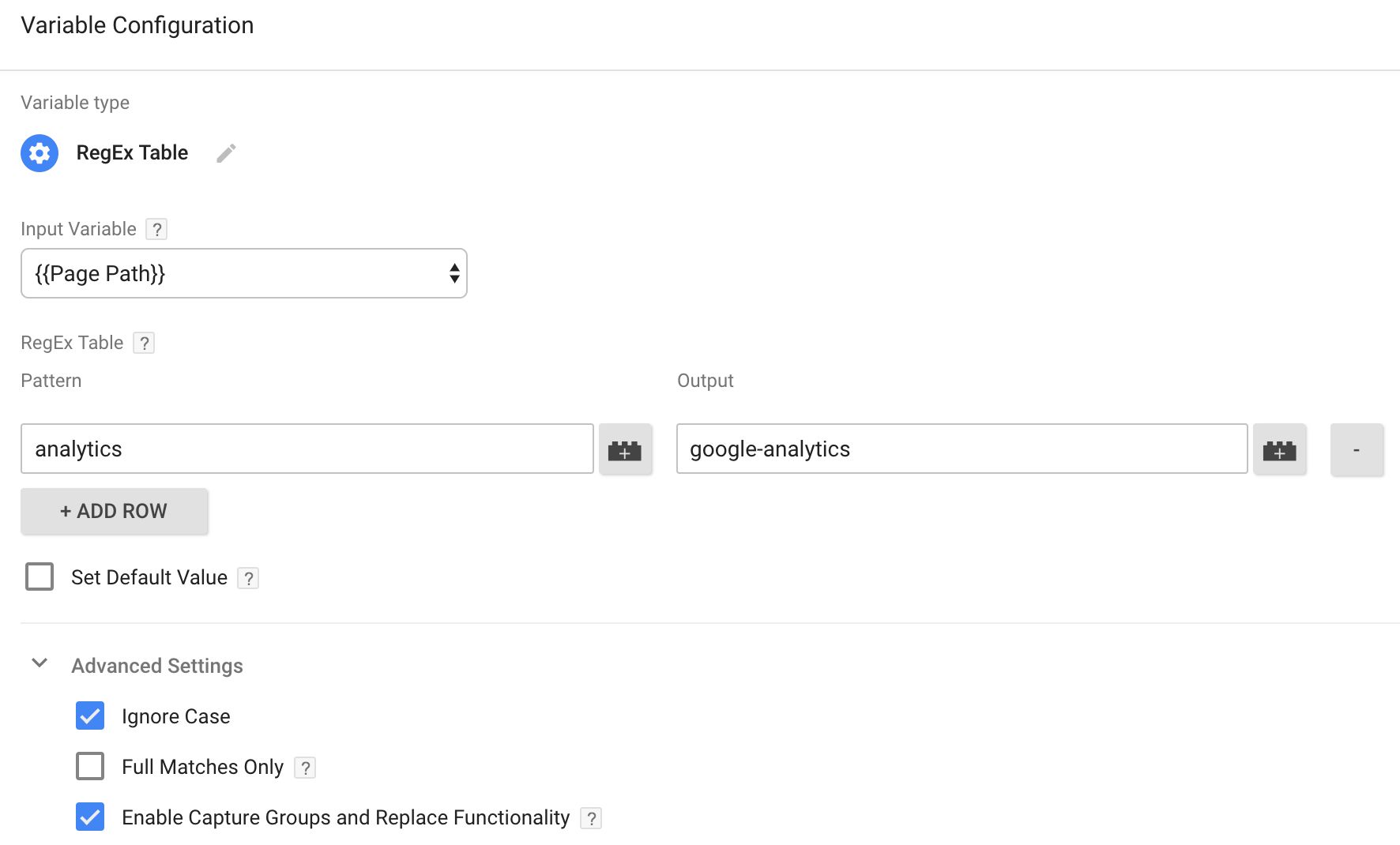
If you leave Full Matches Only unchecked, then Enable Capture Groups and Replace Functionality will replace all matches of the pattern found within the Input Variable with what you have in the Output. For example, if you have a RegEx Table variable that looks like this:
{kind=link}
Then whenever the string “analytics” is found within a page path, it will be replaced with “google-analytics”.
Here is an example:
/analytics/track-users-who-are-offline-in-google-analytics/ becomes /google-analytics/track-users-who-are-offline-in-google-google-analytics/.
Note that the example above only works if Full Matches Only is unchecked. Otherwise the variable would only replace page paths which are exactly analytics, and page paths like that do not exist.
The little help bubble actually recommends to avoid combining this pattern replacement with unchecked Full Matches Only. This is because there’s no validation of the input variable, and you might end up replacing things that you didn’t mean to!
Enable Capture Groups and Replace Functionality is checked by default.
Summary
That’s the RegEx Table in all its simple glory! I know it will make some operations so much simpler. You no longer need to use clumsy Custom JavaScript variables to perform your pattern matches, since the RegEx Table has that built into its modus operandi.
The option to replace any matches with custom strings (in which you can incorporate parts of the match using groups) is pretty powerful, too.
All in all, this is a very welcome addition to Google Tag Manager’s variable offering. It remains to be seen if the Lookup Table still has a place in the table after this, because with the RegEx table you can do exact match lookups, too. The difference is perhaps in the syntax (with Lookup Tables you don’t need to use regular expressions) and performance (lookups will always perform much faster than regular expression matches), though the latter might be very insignificant in the context of a web page.