#GTMTips: Data Layer Variable Versions Explained
Google Tag Manager’s Data Layer is something I’ve touched upon in pretty much all of my articles. It’s such an integral part of what makes a tag management solution great and applicable to a host of business scenarios. I’ve also talked at length about the internal data model of Google Tag Manager, and this #GTMTips post is very much related to this rather murky concept.
In this post, we’ll go over the Data Layer Variable Version selection, and I’ll try to explain just what this selector does.
XThe Simmer Newsletter
Subscribe to the Simmer newsletter to get the latest news and content from Simo Ahava into your email inbox!
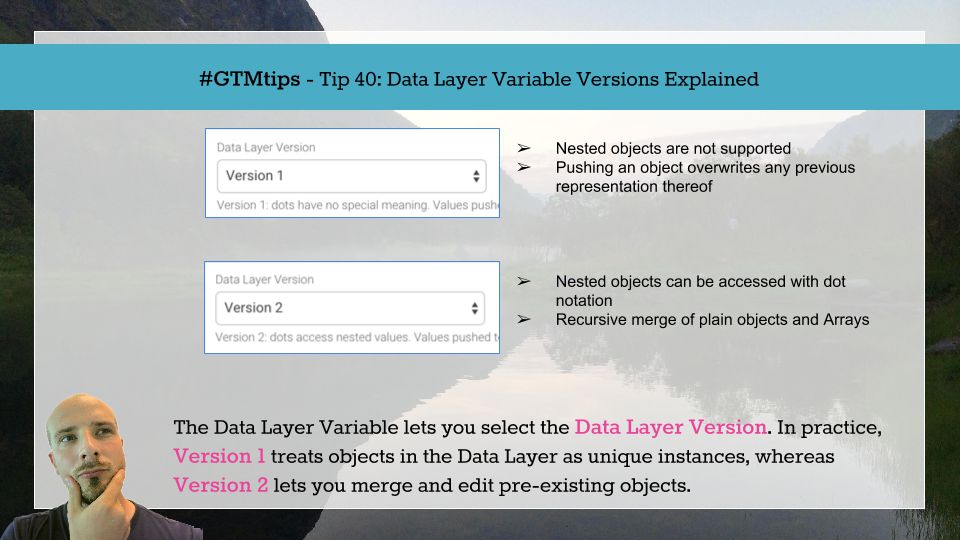
Tip 40: The two faces of the Data Layer Variable
Let’s start by taking a step back. As a technical construct, the “Data Layer” in GTM is a JavaScript Array, which usually comprises a number of plain objects that have been pushed into its innards on a web page.

As you’ve learned from my data model article, GTM doesn’t actually access this Array when you create your Data Layer Variables. Instead, when an object is pushed into dataLayer, it’s made available to the data model of Google Tag Manager, and any Data Layer Variables you create will refer to these instances in the data model rather than directly accessing the Array itself.
Why? To decouple the Array from the internal mechanisms of the connected platform (GTM in this case). This is quite important, as the less GTM needs to rely on the abstract structure of dataLayer, which could be manipulated at any time by either sloppy code or another connected platform, the better.
Now, when you select the Version of the Data Layer Variable, you’re instructing GTM to treat the values in the data model in two different ways.
Version 1
Version 1 of the Data Layer Variable has a very limited reach. Basically, the key-value pair that is pushed into dataLayer needs to be in the root of the object, as Version 1 doesn’t let you access nested keys.
Here’s an example of what would happen with a Version 1 Data Layer Variable that points to key name 'product.price':
// Works because the dots are in the key name, and the key is in the root:
window.dataLayer.push({
'product.price' : '11.99'
});
// Won't work because 'price' is nested in the 'product' object:
window.dataLayer.push({
'product' : {
'price' : '11.99'
}
});
You could, though, access the nested object indirectly with a Version 1 Data Layer Variable by creating the variable for the key 'product', and then manipulating the returned object in a Custom HTML Tag or a Custom JavaScript Variable.
And…yeah. That’s all that Version 1 does. There’s no merging, no special data model functions, no nothing that you can use to further manipulate the retrieved object. So let’s take a look at what happens when I push two different values for the same key ('product'):
window.dataLayer.push({
'product' : {
'price' : '11.99'
}
});
window.dataLayer.push({
'product' : {
'name' : 'Tim Duncan Fan Club Membership'
}
});
In the example above, if I had my Version 1 Data Layer Variable pointing to 'product', it would return a plain object with {'price' : '11.99'} after the first push, and a plain object with {'name' : 'Tim Duncan Fan Club Membership'} after the second.
In essence, any information in the first push is completely overwritten (for this particular Data Layer Variable) by the second push with the same key name ('product').
Version 2
If you want more flexibility, use Version 2 of the Data Layer Variable. This treats objects more like you’d expect if you’re familiar with how JavaScript works.
Instead of bulldozing over existing keys, Version 2 first checks whether a key with that name already exists in the data model. If it does, it recursively merges information in the new push with information in the existing object.
Let’s see an example:
window.dataLayer.push({
'product' : {
'price' : '119.99',
'category' : 'Membership'
}
});
window.dataLayer.push({
'product' : {
'price' : '1199.99',
'name' : 'Tim Duncan Fan Club Membership'
}
});
So, let’s say you’re using Version 2 of the Data Layer Variable, and you’re yet again pointing to the key with name 'product'.
After the first dataLayer.push(), the variable would return a plain object with:
{
'price' : '119.99',
'category' : 'Membership'
}
After the second push, the contents would be:
{
'price' : '1199.99',
'category' : 'Membership',
'name' : 'Tim Duncan Fan Club Membership'
}
Can you see what happened here? Another object with the same key name ('product') is pushed. Version 2 of the Data Layer Variable finds an instance of this key within the data model. Then, it recursively checks each key within this object to see if there are conflicts.
First, it finds that 'price' is in both objects, so there’s a clash. Next, it checks if 'price' is also a plain object or an Array to see if it should perform yet another merge deeper in the structure. However, the value of 'price' is a String, which means that no recursive merge is performed, and the new value overwrites the old one.
Next, it sees that 'category' does not have any conflicts, so it leaves it be in the object. Finally, it finds a completely new key in the second push, 'name', and it merges this key into the existing object in the data model.
So using Version 2 of the Data Layer Variable, resolution of conflicts in object key names is first attempted via a merge of the two objects, but if there are new “primitive” values for any pre-existing keys, their values are overwritten just as they would be with Version 1 of the Data Layer Variable.
So what?
This information could lead to a number of conclusions, but I’m guessing many have the following two questions pop into their minds:
-
Why does the Version 1 still exist? Its numbering alone would mean that it’s inferior.
-
What on earth do I need recursive merge for?
One of the best use cases for Version 1 is with Enhanced Ecommerce. If you’re using the Custom JavaScript Variable method, which I seem to use almost exclusively, you probably want to use Version 1 of the Data Layer when interacting with the 'ecommerce' key. This way, GTM will only access the most recent push into dataLayer. And why is this significant? Take a look at the example below:
window.dataLayer.push({
'ecommerce' : {
'impressions' : [{ ... impressions ... }]
}
});
// Later on the same page
window.dataLayer.push({
'ecommerce' : {
'detail' : { ... product detail view ... }
}
});
// And yet later on the same page
window.dataLayer.push({
'ecommerce' : {
'add' : { ... add to cart action ... }
}
});
If you used Version 2 of the Data Layer Variable to send the Enhanced Ecommerce payload using the Custom JavaScript Variable method, you’ll end up with three Impression payloads, two Product Detail Views, and one Add to Cart action. This is because of the recursive merge of the 'ecommerce' object! I’m guessing your intent is to only send each payload once.
So, if you instead use Version 1 of the Data Layer Variable to access the 'ecommerce' object, GTM will only access the payload that was most recently pushed into dataLayer. This way you’ll end up avoiding the payload multiplication problem.
As for the second point of what recursive merge is good for, there’s a whole universe of possibilities when it comes to merging of objects instead of overwriting previous instances. Examples include:
-
Updating an object as more information is revealed, e.g. collecting a history of interactions on a single page.
-
Updating an object as more information becomes available, e.g. updating a “user” object as certain API calls complete.
-
Making a valid merge of two Enhanced Ecommerce payloads, such as combining
'impressions'with an'add'object.
There are a host of other things you can do with Version 2 of the Data Layer Variable, and those are all detailed in my data model article.
I hope this has been illuminating, and I hope it helps you understand the rationale of having both versions available for the Data Layer Variable.
